
Lekce 7 - MS-SQL krok za krokem: Řazení, Limit a agregační funkce


V předešlém cvičení, Řešené úlohy k 6. lekci MS-SQL, jsme si procvičili nabyté zkušenosti z předchozích lekcí.
Dnes se v MS-SQL tutoriálu podívejme na řazení a agregační funkce.
Řazení
Doposud jsme nijak neřešili pořadí nalezených položek, které nám
dotaz SELECT vrátil. Některé databáze neudržují žádné
pořadí prvků a vrací je tak, jak se jim to zrovna hodilo. MS-SQL je výjimka
a výsledky vrací vždy seřazené podle Id. Databáze nám ale
navrácený výsledek samozřejmě seřadit dokáže, když si o to
řekneme.
Řadit můžeme podle kteréhokoli sloupce. Když budeme řadit podle
Id nebo ponecháme výchozí řazení, máme položky v pořadí, v
jakém byly do databáze vloženy. Dále můžeme řadit podle číselných
sloupců, ale i podle těch textových (řadí se podle abecedy). Řadit
můžeme i podle datumu a všech dalších datových typů, databáze si s tím
vždy nějak poradí. Pojďme si vybrat úplně všechny uživatele a seřaďme
je podle příjmení. Slouží k tomu klauzule ORDER BY (řadit
podle), která se píše na konec dotazu:
SELECT [Jmeno], [Prijmeni] FROM [Uzivatele] ORDER BY [Prijmeni]
Výsledek:
| Jmeno | Prijmeni |
|---|---|
| Václav | Blažek |
| Ondřej | Bohatý |
| Marie | Černá |
| Petr | Černý |
| Vítezslav | Churý |
| Pavel | Dušín |
| ... | ... |
V dotazu by samozřejmě mohlo být i WHERE (psalo by se před
ORDER BY), pro jednoduchost jsme vybrali všechny uživatele.
Řadit můžeme podle několika kritérií (sloupců). Pojďme si uživatele seřadit podle napsaných článků a ty se stejným počtem řaďme ještě podle abecedy:
SELECT [Jmeno], [Prijmeni], [PocetClanku] FROM [Uzivatele] ORDER BY [PocetClanku], [Prijmeni]
Výsledek:
| Jmeno | Prijmeni | PocetClanku |
|---|---|---|
| Matěj | Horák | 0 |
| Michal | Krejčí | 0 |
| Petr | Černý | 1 |
| Miroslav | Kučera | 1 |
| Vladimír | Pokorný | 1 |
| Jana | Veselá | 1 |
| František | Veselý | 1 |
| Ludmila | Dvořáková | 2 |
| Věra | Svobodová | 2 |
| Jiří | Veselý | 2 |
| ... | ... | ... |
Směr řazení
Určit můžeme samozřejmě i směr řazení. Můžeme řadit vzestupně
(výchozí směr) klíčovým slovem ASC a sestupně klíčovým
slovem DESC. Zkusme si udělat žebříček uživatelů podle
počtu článků. Ti první jich tedy mají nejvíce, řadit budeme sestupně.
Ty se stejným počtem článků budeme řadit ještě podle abecedy:
SELECT [Jmeno], [Prijmeni], [PocetClanku] FROM [Uzivatele] ORDER BY [PocetClanku] DESC, [Prijmeni]
Výsledek:
| Jmeno | Prijmeni | PocetClanku |
|---|---|---|
| Petr | Dvořák | 18 |
| Jan | Novák | 17 |
| Eva | Kučerová | 12 |
| Tomáš | Marný | 12 |
| Pavel | Dušín | 9 |
| Otakar | Kovář | 9 |
| ... | ... | ... |
DESC je třeba vždy uvést, vidíte, že řazení podle
příjmení je normálně sestupné, protože jsme DESC napsali jen
k PocetClanku.
Agregační funkce
Databáze nám nabízí spoustu tzv. agregačních funkcí. To jsou funkce, které nějakým způsobem zpracují více hodnot a jako výsledek vrátí hodnotu jednu.
COUNT (Počet)
Příkladem takové funkce je funkce COUNT(), která vrátí
počet řádků v tabulce, splňující nějaká kritéria. Spočítejme, kolik
z uživatelů napsalo alespoň jeden článek:
SELECT COUNT(*) FROM [Uzivatele] WHERE [PocetClanku] > 0;
Výsledek:
| 29 |
Na COUNT() se ptáme pomocí SELECT, není to
příkaz, je to funkce, která se vykoná nad řádky a její výsledek je
vrácen selectem. Funkce má stejně jako v jiných programovacích jazycích
(alespoň ve většině z nich) závorky. Ta hvězdička v nich znamená, že
nás zajímají všechny sloupce. Můžeme totiž počítat třeba jen
uživatele, kteří mají vyplněné jméno (přesněji kteří ho nemají
NULL, ale to nechme na další lekce).
Pozn.: Určitě by vás napadl i jiný způsob, jak tohoto výsledku
docílit. Jednoduše byste si vybrali nějakou hodnotu jako doposud (třeba
jméno), tyto řádky byste si přenesli do své aplikace a spočítali, kolik
jmen je. Data byste poté zahodili. Takový přenos je ale zbytečně náročný
na databázi a zpomaloval by aplikaci. COUNT() přenáší jen
jedno jediné číslo. Nikdy nepočítejte pomocí výběru hodnoty, pouze
funkcí COUNT()!
AVG()
AVG() počítá průměr z daných hodnot. Podívejme se, jaký
je průměrný počet článků na uživatele:
SELECT AVG([PocetClanku]) FROM [Uzivatele];
Výsledek:
| 5 |
SUM()
SUM() vrací součet hodnot. Podívejme se, kolik článků
napsali dohromady lidé narození po roce 1980:
SELECT SUM([PocetClanku]) FROM [Uzivatele] WHERE [DatumNarozeni] > '1980-12-31';
Výsledek:
| 57 |
MIN()
Funkce MIN() vrátí minimum (nejmenší hodnotu). Najděme
nejnižší datum narození:
SELECT MIN([DatumNarozeni]) FROM [Uzivatele];
Výsledek:
| 1935-05-15 |
Pozor, pokud bychom chtěli vybrat i jméno a příjmení, tento kód nebude fungovat:
-- Tento kód nebude fungovat SELECT [jmeno], [prijmeni], MIN([DatumNarozeni]) FROM [Uzivatele];
Agregační funkce pracuje s hodnotami více sloupců a vybrané sloupce
(Jmeno a Prijmeni) nebudou nijak souviset s hodnotou
MIN(). Problém bychom mohli vyřešit poddotazem nebo ještě
jednodušeji se funkcím MIN() a MAX() úplně vyhnout
a použít místo nich řazení a TOP:
SELECT TOP 1 [Jmeno], [DatumNarozeni] FROM [Uzivatele] ORDER BY [DatumNarozeni]
Výsledek:
| Jmeno | DatumNarozeni |
| Alfons | 1935-05-15 |
MAX()
Obdobně jako MIN() existuje i funkce MAX().
Najděme maximální počet článků od 1 uživatele:
SELECT MAX([PocetClanku]) FROM [Uzivatele];
Výsledek:
| 18 |
MS-SQL má ještě nějaké agregační funkce, ale ty pro nás již nejsou zajímavé.
Seskupování (Grouping)
Položky v databázi můžeme seskupovat podle určitých kritérii. Seskupování používáme téměř vždy spolu s agregačními funkcemi. Pojďme seskupit uživatele podle jména:
SELECT [Jmeno] FROM [Uzivatele] GROUP BY [Jmeno];
Výsledek:
| Jmeno |
|---|
| Alfons |
| Eva |
| František |
| Jan |
| Jana |
| ... |
Vidíme, že každé jméno je zde zastoupeno jen jednou, i když je v
databázi vícekrát. Přidejme nyní kromě jména i počet jeho zastoupení v
tabulce, uděláme to pomocí agregační funkce COUNT(*):
SELECT [Jmeno], COUNT(*) FROM [Uzivatele] GROUP BY [Jmeno];
Výsledek:
| Jmeno | |
|---|---|
| Alfons | 1 |
| Eva | 1 |
| František | 1 |
| Jan | 2 |
| Jana | 1 |
| ... |
Vidíme, že třeba Jany máme v databázi dva.
AS
Pro zjednodušení si můžeme v dotazu vytvořit aliasy, tedy přejmenovat
třeba nějaký dlouhý sloupec, aby byl dotaz přehlednější. S tímto se
ještě setkáme u dotazů přes více tabulek, kde je to velmi užitečné. U
tabulek AS používáme ke zjednodušení operací uvnitř dotazu.
U sloupců se AS používá k tomu, aby aplikace viděla data pod
jiným názvem, než jsou skutečně v databázi. To může být užitečné
zejména u agregačních funkcí, protože pro ně v databázi není žádný
sloupec a mohlo by se nám s jejich výsledkem špatně pracovat. Upravme si
poslední dotaz:
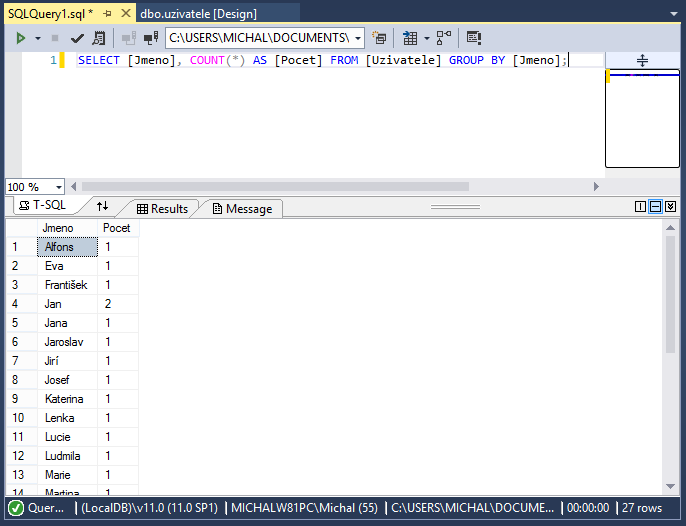
SELECT [Jmeno], COUNT(*) AS [Pocet] FROM [Uzivatele] GROUP BY [Jmeno];
Výsledek:
V následujícím cvičení, Řešené úlohy k 7. lekci MS-SQL, si procvičíme nabyté zkušenosti z předchozích lekcí.
