
Lekce 12 - Seznam v Pythonu

V předešlém cvičení, Řešené úlohy k 10.-11. lekci Pythonu, jsme si procvičili nabyté zkušenosti z předchozích lekcí.
V dnešním Python tutoriálu si představíme seznam. Naučíme se ho vytvářet, procházet jím a pracovat s jeho položkami pomocí funkcí a metod.
Seznam
Představme si, že si chceme uložit nějaké údaje o více prvcích.
Např. chceme v paměti uchovávat 10 čísel, hrací pole šachovnice nebo
jména 50 uživatelů. Asi nám dojde, že v programování existuje nějaká
lepší cesta než začít mechanicky vytvářet proměnné
uzivatel1, uzivatel2 až např.
uzivatel50. Nehledě na to, že proměnných můžeme potřebovat
třeba 1000! Jak by se v tom potom hledalo? Brrr, takto ne 
Potřebujeme-li uchovávat větší množství proměnných stejného
typu, tento problém nám řeší seznam. Můžeme si
ho představit jako řadu přihrádek, kdy v každé máme uložený jeden
prvek. Přihrádky jsou očíslované tzv. indexy, přičemž
první přihrádka má index 0:

Programovací jazyky se velmi liší v tom, jak se seznamem pracují. V některých jazycích (zejména starších, kompilovaných) nebylo možné za běhu programu vytvořit seznam s dynamickou velikostí (např. mu dát velikost podle nějaké proměnné). Seznam se musel deklarovat s konstantní velikostí přímo ve zdrojovém kódu. Toto se obcházelo tzv. pointery a vlastními datovými strukturami, což často vedlo k chybám při manuální správě paměti a k nestabilitě programu (např. v C++). Tyto druhy seznamů se často označují jako pole.
Python je interpretovaný programovací jazyk, takže neposkytuje pole s pevnou velikostí. Místo toho dostáváme dynamické seznamy, do kterých můžeme přidávat a z nichž lze odebírat položky podle libosti.
Mnoho vestavěných funkcí a metod v Pythonu se seznamy pracuje nebo seznamy vrací. Jde tedy o klíčovou datovou strukturu.
Pro hromadnou manipulaci s prvky seznamu se používají cykly.
Práce se seznamem
V následujících krocích si ukážeme, jak seznam deklarovat a jak jej naplnit vlastními daty.
Deklarace a inicializace seznamu
Seznam deklarujeme a inicializujeme pomocí hranatých závorek:
cisla = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
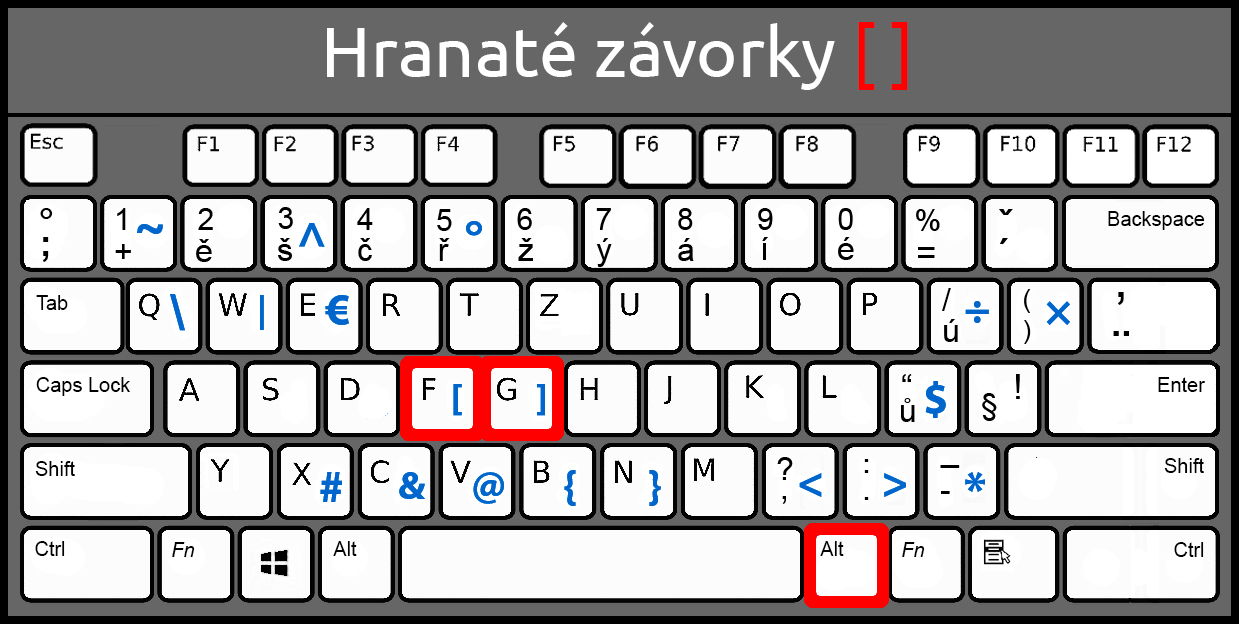
Hranaté závorky se na české klávesnici napíší pomocí klávesy pravý ALT a písmeny F a G:
Slovo cisla je samozřejmě název naší proměnné. Nyní tedy
máme seznam deseti hodnot typu int v proměnné
cisla.
Přístup k prvkům seznamu
K jednotlivým prvkům uloženým v seznamu přistupujeme
prostřednictvím indexů uvnitř hranatých závorek. Prvním
indexem je vždy 0:
cisla = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
print(cisla[0])
cisla[5] = 50
print(cisla[5])V konzoli uvidíme výstup:
Výstup seznamu:
1
50
Vytvoření seznamu pomocí
funkce range()
Plnit seznam ručně daty by bylo příliš pracné. Pojďme tedy zkusit
využít nám již známou funkci range() a naplňme seznam
hodnotami od 1 do 10. Protože ale funkce
range() nevrací seznam, nýbrž obecnou sekvenci, převedeme ji na
seznam pomocí funkce list():
cisla = list(range(1,11))
Když pracujeme se seznamem, často potřebujeme projít všechny jeho prvky. S tím nám pomůže AI autocomplete. Stačí napsat začátek cyklu:
for ci ...
AI v editoru sama nabídne doplnění celého cyklu
for. To se hodí hlavně ve chvíli, kdy už víme, co chceme
udělat:

Ukažme si celý kód včetně výpisu:
cisla = list(range(1,11))
for cislo in cisla:
print(cislo, end=" ")Takto vypadá výstup v konzoli:
Výpis seznamu pomocí cyklu for:
1 2 3 4 5 6 7 8 9 10
V některých jazycích má cyklus for také
variantu foreach (například v C#). V Pythonu
se for cyklus používá pro iteraci přes prvky v kolekci, a je
tedy ekvivalentem k foreach cyklu v jiných jazycích, jako je
např. C#.
Mějme na paměti, že pomocí cyklu for nejsme schopni jakkoli
editovat prvky v seznamu. V každé iteraci je v cyklu reference na
neměnnou položku. Následující příklad tedy nebude
fungovat:
# Tento kód je chybný cisla = list(range(1, 11)) for cislo in cisla: cislo += 1 print(cisla)
Zápis cislo += 1 je zkrácená verze zápisu
cislo = cislo + 1. V Pythonu se používá naprosto běžně ke
zkrácení operací s proměnnými. Analogicky funguje i s ostatními operátory
(např. -=, *=, /= atd.).
Výsledek bude stále:
Pokus o změnu v seznamu během cyklu for:
[1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
Funkce print(cisla) vytiskne obsah seznamu v
hranatých závorkách.
Úprava obsahu seznamu s
range()
V předchozím příkladu jsme totiž změnili pouze hodnoty proměnných v cyklu, nikoli hodnoty skutečného seznamu. Pakliže chceme upravit hodnoty seznamu v cyklu, musíme k nim přistoupit na základě jejich indexů:
cisla= list(range(1, 11))
for i in range(len(cisla)):
cisla[i] += 1
print(cisla)Funkce len() vrací počet prvků v seznamu.
Řetězcové seznamy
Při práci se seznamy nejsme limitováni používáním čísel. Založme si ručně seznam Simpsonových:
simpsons = ["Homer", "Marge", "Bart", "Lisa", "Maggie"]
K iteraci položek v seznamu můžeme kromě funkce range()
použít také funkci enumerate(). Její výhodou je, že nám
vrátí jak index položky, tak i položku samotnou:
simpsons = ["Homer", "Marge", "Bart", "Lisa", "Maggie"]
for i, prvek in enumerate(simpsons):
print(f"{i}: {prvek}")Seznamy často slouží k ukládání mezivýsledků, které se potom dále v programu používají. Když nějaký výsledek potřebujeme desetkrát, stačí ho namísto desetkrát spočítat pouze jednou a uložit ho do seznamu. Odtud poté výsledek jen načteme.
Ořezávání
V Pythonu je možné dostat jen "ořezanou" část seznamu. Syntaxe je
podobná jako v případě přístupu k položkám. Jen upřesníme více
argumentů, podobně jako u funkce range():
cisla = range(10)
print(list(cisla))
print(list(cisla[0:5]))
print(list(cisla[2:8]))
print(list(cisla[1:7:2]))
print(list(cisla[2:9:2]))
print(list(cisla[6:]))Varianty argumentů:
nazev_seznamu[m]vybere jediný prvek.nazev_seznamu[m:n]vybere prvky v rozsahumažn-1(prveknuž zahrnutý není).nazev_seznamu[m:n:i]vyberema každý i-tý prvek don-1.
Jednotlivé argumenty, jež určují, co chceme vybrat, lze i vynechat.
Můžeme tedy napsat [::2], což nám vybere každý druhý prvek v
seznamu.
Pokud není uveden první prvek, automaticky se začíná od
začátku seznamu (index 0). Pokud není uveden druhý
prvek, výběr pokračuje až do konce seznamu. Pokud není specifikováno, o
kolik prvků se má postupovat, výchozí hodnota je 1, což
znamená, že se vybírá každý prvek v zadaném intervalu.
Metody a funkce pro práci se seznamy
Základní operace se seznamy v Pythonu jsme si již představili. Teď se zaměříme na prohloubení našich dovedností s využitím různých metod a funkcí, které Python pro efektivní a flexibilní manipulaci se seznamy nabízí. Umožňují nám provádět operace jako třídění, invertování, přidávání nebo odstraňování prvků a mnoho dalšího. S těmito nástroji se stává práce se seznamy v Pythonu mnohem jednodušší a intuitivnější.
Metody pro práci se seznamy
Existuje mnoho metod určených přímo pro práci se seznamy. Pojďme se podívat na ty nejpoužívanější. Jednotlivé metody si představíme postupně a uvedeme si také jednoduché příklady.
Metoda append()
Metoda append() vloží novou položku na konec seznamu:
cisla = [2, 3, 16, 21]
cisla.append(13)
print(cisla)Metoda insert()
Metoda insert() vloží novou položku na konkrétní index v
seznamu. Prvním parametrem metody je index, na který chceme vložit novou
položku. Druhým parametrem je samotná položka:
cisla = [2, 3, 16, 21]
cisla.insert(1, 10)
print(cisla)Metoda extend()
Metoda extend() připojí všechny položky z dané sekvence do
seznamu:
cisla = [2, 3, 16, 21]
dalsi_cisla = [13, 18, 24]
cisla.extend(dalsi_cisla)
print(cisla)Metoda clear()
Metoda clear() odebere všechny položky ze seznamu. Stejného
výsledku můžeme dosáhnout zápisem del seznam[:]:
cisla = [2, 3, 16, 21]
cisla.clear()
print(cisla)Metoda remove()
Metoda remove() odebere danou položku ze seznamu. V případě,
že hledaná položka není v seznamu nalezena, metoda remove()
vyvolá výjimku:
cisla = [2, 3, 16, 21]
cisla.remove(3)
print(cisla)Metoda reverse()
Metoda reverse() otočí pořadí položek v seznamu tak, že
první položka je nyní poslední, druhá je předposlední atd.:
cisla = [2, 3, 16, 21]
cisla.reverse()
print(cisla)Metoda count()
Metoda count() vrací počet výskytů dané položky v
seznamu:
cisla = [2, 3, 16, 21, 2, 2, 3]
pocet_dvojek = cisla.count(2)
print(pocet_dvojek)Metoda sort()
Metoda sort() seznam seřadí. Je dokonce tak chytrá, že
pracuje podle toho, co máme v seznamu uložené. Textové řetězce seřadí
podle abecedy, čísla podle velikosti atd. Zkusme si setřídit a vypsat naši
rodinku Simpsonových:
simpsons = ["Homer", "Marge", "Bart", "Lisa", "Maggie"]
simpsons.sort()
for s in simpsons:
print(s, end = " ")Když si nepamatujeme, jak v Pythonu seřadit seznam, zkusme se zeptat AI. Do Copilota zadejme například: "Setřiď mi seznam řetězců v Pythonu podle abecedy.".
Metoda index()
Metoda index() vrací index prvního výskytu hledané položky.
Pokud položka není nalezena, metoda vyvolá výjimku ValueError.
Metoda si hledanou položku bere jako parametr. Dále můžeme upřesnit dva
další číselné parametry, které určují počáteční a konečný index,
mezi nimiž má být položka hledána. Například umožníme uživateli zadat
jméno Simpsona a řekneme mu, na které pozici je Simpson uložený. Nyní to
pro nás nemá hlubší význam, protože položka je pouze jednoduchý
string. Metoda se nám však bude velmi hodit ve chvíli, kdy v
seznamu budeme mít uložené plnohodnotné objekty. Následující příklad
tedy berme jako takovou přípravu:
simpsons = ["Homer", "Marge", "Bart", "Lisa", "Maggie"]
simpson = input("Ahoj, zadej svého oblíbeného Simpsona (z rodiny Simpsonů): ")
if simpson in simpsons:
pozice = simpsons.index(simpson);
print(f"Jo, to je můj {pozice+1}. nejoblíbenější Simpson!")
else:
print("Hele, tohle není Simpson!")A v konzoli vidíme:
Využití metody index():
Ahoj, zadej svého oblíbeného Simpsona (z rodiny Simpsonů):
Bart
Jo, to je můj 3. nejoblíbenější Simpson!
Funkce pro práci se seznamy
Python také obsahuje několik globálních funkcí pro práci se seznamem. Tyto funkce nejsou specifické pouze pro seznamy, ale fungují také u jiných kolekcí nebo sekvencí, jako jsou n-tice, řetězce, množiny a slovníky.
Funkce len()
S touto funkcí jsme se již setkali. Vrací nám počet všech položek v seznamu:
cisla = [2, 3, 16, 21, 2, 2, 3]
pocet_prvku = len(cisla)
print(pocet_prvku)Funkce min(), max(),
sum()
Jedná se o matematické funkce:
min()vrací nejmenší z položek v seznamu.max()vrací největší z položek v seznamu.sum()vrací součet všech hodnot položek v seznamu (u číselných typů).
Podívejme se na příklad:
cisla = [5, 10, 15, 20, 25]
nejmensi = min(cisla)
print(f"Nejmenší číslo v seznamu je: {nejmensi}")
nejvetsi = max(cisla)
print(f"Největší číslo v seznamu je: {nejvetsi}")
soucet = sum(cisla)
print(f"Součet všech čísel v seznamu je: {soucet}")Funkce sorted()
Tato funkce nápadně připomíná metodu sort(), ale na rozdíl
od ní vrací setříděnou kopii původního seznamu, aniž
jej jakkoli ovlivní:
cisla = [2, 8, 1, 5, 3]
setridena_cisla = sorted(cisla)
print(f"Neuspořádaná čísla: {cisla}")
print(f"Setříděná čísla: {setridena_cisla}")Homogennost seznamů v Pythonu
Zatímco v jiných programovacích jazycích bývají seznamy omezeny na uchovávání prvků jednoho datového typu, Python nám dovoluje vytvářet seznamy, které obsahují různé datové typy. Například:
smes = [1, "Ahoj", 3.14, [1, 2, 3]]
Seznam smes obsahuje celé číslo, řetězec, desetinné
číslo a jiný seznam. Takové seznamy jsou považovány za
nehomogenní. Ačkoli jsou nehomogenní seznamy v některých
situacích užitečné, často také působí komplikace. Například
pokusíme-li se použít některé funkce, které vyžadují homogenní seznam
(např. funkce určené pro práci pouze s čísly), narazíme na chyby. Když
se chystáme třeba sečíst všechny prvky v seznamu, musíme se ujistit, že
všechny prvky v seznamu jsou čísla.
Vždy je nutné ujistit se, že všechny prvky v seznamu jsou kompatibilní s operacemi, které se seznamem budeme provádět.
To by pro dnešek stačilo. Můžete si se seznamem hrát a experimentovat 😉
Shrnutí lekce
Seznam ukládá více hodnot do jedné proměnné. Prvky mají indexy a
první index je 0. Seznam vytváříme hranatými závorkami a
přes indexy čteme nebo měníme jeho položky. Pomocí cyklu for
seznam procházíme, část seznamu získáme ořezáváním. Seznamy upravujeme
metodami jako append(), insert(),
remove(), sort() nebo reverse(). Funkce
len(), min(), max() a sum()
slouží ke zjištění délky, krajních hodnot nebo součtu prvků, zatímco
sorted() vytvoří seřazenou kopii seznamu.
V následujícím kvízu, Kvíz - Cykly a seznamy v Pythonu, si vyzkoušíme nabyté zkušenosti z předchozích lekcí.
