
Lekce 9 - Oracle krok za krokem: Dotazy přes více tabulek (JOIN)


V předchozím kvízu, Kvíz - Výběr dat, řazení a datové typy v Oracle, jsme si ověřili nabyté zkušenosti z předchozích lekcí.
Dnes začneme dělat na jednoduchém redakčním systému, který může připomínat ten zde na ITnetwork. Ukážeme si dotazování přes více tabulek.
Konceptuální model
V následujících dílech si tedy v databázi vytvoříme takový zjednodušený ITnetwork. Pobavme se nejprve o tom, jak to bude vypadat. Dnes stihneme pochopitelně jen malou část. Protože obrázek někdy řekne více, než tisíc slov, začněme právě jím.
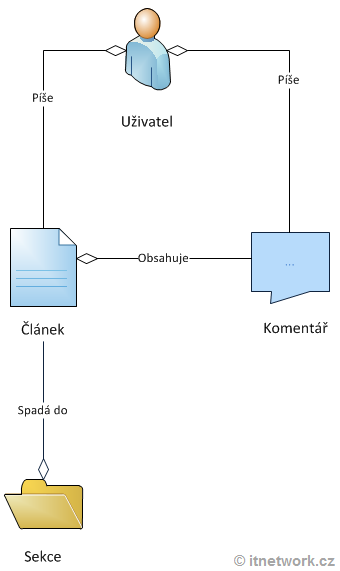
Co vidíte je tzv. konceptuální model. Je vytvořený pomocí notace (grafického jazyka) UML a v praxi se takovéto diagramy velmi často tvoří předtím, než začneme psát nějaký kód. Dobře si tak nejprve rozmyslíme, co že to vlastně chceme udělat.
Vidíme, že v systému figuruje uživatel, který může psát komentáře a články. Články spadají do sekcí. Jedná se tedy o databázi takového velmi jednoduchého redakčního systému, který si díky ITnetwork jistě dokážete představit.
Příprava tabulek a dat
Dnes se zaměříme na dotazy přes více tabulek. Pojďme si nejprve nějaké tabulky vytvořit. Bohatě nám budou stačit uživatelé a články.
Uživatelé
Protože uživatel bude vypadat trochu jinak, než nám vypadal doteď, založíme si tabulku uzivatele znovu. Tu současnou tedy dropneme:
DROP TABLE uzivatele;
Následně vytvoříme tabulku novou. Uživatel zde bude mít (kromě id) přezdívku, email a heslo:
CREATE TABLE uzivatele ( uzivatele_id INT GENERATED ALWAYS AS IDENTITY (START with 1 INCREMENT by 1), prezdivka VARCHAR2(155), email VARCHAR2(155), heslo VARCHAR2(255), PRIMARY KEY (uzivatele_id) );
Do uživatelů si rovnou nějaké vložíme:
INSERT INTO uzivatele (prezdivka, email, heslo) WITH zaznamy AS ( SELECT 'Míša', '[email protected]', 'dGg#@$DetA53d' FROM dual UNION ALL SELECT 'David', '[email protected]', '$#fdfgfHBKBKS' FROM dual UNION ALL SELECT 'Denny', '[email protected]', 'Jmls_aSW2RFss' FROM dual UNION ALL SELECT 'Emma', '[email protected]', 'fw8QT32qmcsld' FROM dual ) SELECT * FROM zaznamy;
Články
Článek bude propojen s uživatelem, který ho napsal, tedy s jeho autorem. Tabulky propojíme tak, že do tabulky clanky přidáme sloupec s id autora. Tam bude hodnota id uživatele (tedy primární klíč z tabulky uzivatele), který článek napsal.
Hovoříme o vazbě 1:N (1 uživatel má N (několik) článků a každý článek patří právě jednomu uživateli). Část (zde článek) má vždy uložené id celku (zde uživatel) kam patří.
Článek bude obsahovat (opět kromě svého id) ID autora, krátký popis, URL, klíčová slova, titulek, obsah a datum publikace. Založme si tabulku clanky:
CREATE TABLE clanky ( clanky_id INT GENERATED ALWAYS AS IDENTITY (START with 1 INCREMENT by 1), autor_id INT, popis VARCHAR2(155), url VARCHAR2(155), klicova_slova VARCHAR2(155), titulek VARCHAR2(155), obsah VARCHAR2(4000), publikovano DATE, PRIMARY KEY (clanky_id) );
Všimněme si, že sloupec obsah má datový typ
VARCHAR2(4000), což je v Oracle standardní maximální délka
VARCHAR2. Kdybychom chtěli tento limit navýšit, museli bychom nastavit
parametr MAX_STRING_SIZE
na EXTENDED.
Dále přidáme články a k nim přiřadíme uživatele jako autory. Vzal jsem 4 články zde z ITnetwork, které jsem značně zkrátil a zjednodušil. Dotaz bude následující:
INSERT INTO clanky (autor_id, popis, url, klicova_slova, titulek, obsah, publikovano) WITH zaznamy AS ( SELECT 1, 'Co je to algoritmus? Pokud to nevíte, přečtěte si tento článek.', 'co-je-to-algoritmus', 'algoritmus, co je to, vysvětlení', 'Algoritmus', 'Když se bavíme o algoritmech, pojďme se tedy shodnout na tom, co ten algoritmus vůbec je. Jednoduše řečeno, algoritmus je návod k řešení nějakého problému. Když se na to podíváme z lidského pohledu, algoritmus by mohl být třeba návod, jak ráno vstát. I když to zní jednoduše, je to docela problém. Počítače jsou totiž stroje a ty nemyslí. Musíme tedy dopodrobna popsat všechny kroky algoritmu. Tím se dostáváme k první vlastnosti algoritmu - musí být elementární (skládat se z konečného počtu jednoduchých a snadno srozumitelných kroků, tedy příkazů). "Vstaň z postele" určitě není algoritmus. "Otevři oči, sundej peřinu, posaň se, dej nohy na zem a stoupni si" - to už zní docela podrobně a jednalo by se tedy o pravý algoritmus. My se však budeme pohybovat v IT, takže budeme řešit problémy jako seřaď prvky podle velikosti nebo vyhledej prvek podle jeho obsahu. To jsou totiž 2 základní úlohy, které počítače dělají nejčastěji a které je potřeba dokonale promýšlet a optimalizovat, aby trvaly co nejkratší dobu. Z dalších příkladů algoritmů mě napadá třeba vyřeš kvadratickou rovnici nebo vyřeš sudoku.', '21.3.2012' FROM dual UNION ALL SELECT 2, 'Bakterie jsou obdoba buněčného automatu v kombinaci s hrou.', 'bakterie-bunecny-automat', 'bakterie, automat, algoritmus', 'Bakterie', 'Bakterie jsou obdoba buněčného automatu, který vymyslel britský matematik John Horton Conway v roce 1970. Celou tuto hru řídí čtyři jednoduchá pravidla:/n/n 1. Živá bakterie s méně, než dvěma živými sousedy umírá./n 2. Živá bakterie s více, než třemi živými sousedy umírá na přemnožení./n 3. Živá bakterie s dvoumi nebo třemi sousedy přežívá beze změny do další generace./n 4. Mrtvá bakterie, s přesně třemi živými sousedy, opět ožívá./n Tyto zdánlivě naprosto primitivní pravidla dokáží za správného počátečního rozmístění bakterií vytvořit pochodující skupinky, shluky "vystřelující" pochodující pětice, překvapivě složité souměrné exploze, oscilátory (periodicky kmitající skupinky), či nekonečnou podívanou na to, jak složité a dokonalé obrazce dokáží tyto dvě podmínky vytvořit. Celý program je koncipován jako hra, máte za úkol vytvořit co nejdéle žijící kolonii. <a href="soubory/bakterie.zip" ', '14.2.2012' FROM dual UNION ALL SELECT 3, 'Cheese Mouse je oddechová plošinovka.', 'cheese-mouse-oddechova-plosinovka', 'myš, sýr, hra', 'Cheese Mouse', 'Cheese mouse je plošinovka s "horkou ostrovní atmosférou", kde ovládáte myš a musíte se dostat k sýru. V tom vám ale brání nejrůznější nástrahy a nepřatelé jako hadi, krysy, pirane, ale i roboti, mumie a nejrůznější havěť. Hru s několika petrobarevnými světy jsem dělal ještě na základní škole s Veisenem a může se pochlubit 2. místem v Bonusweb game competition, kde vyhrála 5.000 Kč. Vznikala v Game makeru o letních prázdninách, ještě v bezstarostném dětství, což značně ovlivnilo její grafickou stránku. Rád si ji občas zahraji na odreagování a zlepšní nálady. <a href="soubory/cheesemouse.zip" />', '22.6.2004' FROM dual UNION ALL SELECT 2, 'Pacman je remake kultovní hry.', 'pacman-remake', 'pacman, remake, pampuch, hra, zdarma', 'Pacman', 'Jedná se o naprosto základní verzi této hry s editorem levelů, takže si můžete vytvořit svá vlastní kola. Postupem času ji hodlám ještě trochu upravit a přidat nějaké nové prvky, fullscreen a lepší grafiku. Engine hry bude také základem mého nového projektu Geckon man, který je zatím ve fázi psaní scénáře. <a href="soubory/pacman.zip" />', '3.6.2011' FROM dual ) SELECT * FROM zaznamy;
Jestliže na vás vyskočí hláška "Enter value for ...",
žádnou hodnotu nezadávejte, a klikejte pouze na OK. Tato hláška jde vypnout
příkazem SET DEFINE OFF.
Dotazy přes více tabulek
Nyní máme v databázi články a k nim přiřazené uživatele. Pojďme si udělat dotaz přes tyto 2 tabulky, získejme články a k nim připojme přezdívky jejich uživatelů. Slovo připojme jsem nepoužil náhodou, příkaz pro spojení 2 tabulek se totiž jmenuje JOIN. Napišme si dotaz a poté si ho vysvětleme. Dotazy již budeme psát na více řádků, abychom se v tom vyznali.
SELECT titulek, prezdivka FROM clanky JOIN uzivatele ON autor_id = uzivatele_id ORDER BY prezdivka;
Výsledek:
| TITULEK | PREZDIVKA |
|---|---|
| Bakterie | David |
| Pacman | David |
| Cheese Mouse | Denny |
| Algoritmus | Míša |
Na prvním řádku příkazu SELECT pracujeme se sloupci úplně
stejně, jako kdyby byly v jedné tabulce, jednoduše vyjmenujeme, co nás
zajímá. Jelikož vybíráme články a k nim připojujeme uživatele, budeme
vybírat z tabulky clanky. Připojení dat z jiné tabulky uděláme
pomocí příkazu JOIN, kde uvedeme tabulku, kterou připojujeme, a
poté klauzuli ON. Klauzule ON je podobná jako
WHERE, jen platí pro připojovanou tabulku a ne pro tu, ze které
primárně vybíráme. V podmínce uvedeme, aby se ke každému článku
připojil ten uživatel, jehož uzivatele_id je uvedeno ve sloupci
autor_id. Výsledek jsme seřadili podle přezdívky uživatelů.
Kdybychom chtěli jen nějaké články, normálně bychom před
ORDER BY uvedli ještě WHERE, jak jsme zvyklí.
INNER JOIN a
OUTER JOIN
INNER (vnitřní) a OUTER (vnější)
JOIN jsou 2 typy příkazu JOIN. Fungují úplně
stejně, jediný rozdíl je v tom, co se stane, když položka, na kterou se
vazba odkazuje, neexistuje.
INNER JOIN
Pokud uvedeme v SQL dotazu pouze JOIN, pokládá ho Oracle databáze za tzv. INNER JOIN. Pokud by v našem případě neexistoval uživatel s id, které je u článku uvedeno, článek bez uživatele by vůbec nebyl ve výsledcích obsažen. Vazba je nerozdělitelná.
Pojďme si to zkusit, přidejme si článek, který bude odkazovat na id neexistujícího uživatele:
INSERT INTO clanky (autor_id, popis, url, klicova_slova, titulek, obsah, publikovano) VALUES (99, 'Článek s neexistujím uživatelem slouží pro vyzkoušení typů JOINů.', 'clanek-bez-autora', 'clanek, join, autor, chybejici', 'Článek bez autora', 'Tento článek je přiřazen neexistujícímu uživateli s ID 99 a slouží k vyzkoušení různých typů JOINů v MySQL databázi.', '21.10.2012');
Vložený článek se odkazuje na uživatele s uzivatele_id 99, který v databázi není. Spusťme si nyní znovu náš SQL dotaz s JOINem. Pro přehlednost je lepší uvést, že chceme INNER JOIN:
SELECT titulek, prezdivka FROM clanky INNER JOIN uzivatele ON autor_id = uzivatele_id ORDER BY prezdivka;
Výsledek:
| TITULEK | PREZDIVKA |
|---|---|
| Bakterie | David |
| Pacman | David |
| Cheese Mouse | Denny |
| Algoritmus | Míša |
Výsledek je stále stejný, článek bez autora mezi výsledky není.
LEFT OUTER JOIN
Vnější JOINy umožňují vybírat i ty výsledky, které se
nepodařilo spojit z důvodu chybějících položek. Zkusme si tzv.
LEFT JOIN, který výsledek uzná, pokud existuje levá část
vazby (zde článek) a pravá (ta připojovaná, zde uživatel) neexistuje. Do
hodnot sloupců z připojované části se vloží NULL:
SELECT titulek, prezdivka FROM clanky LEFT JOIN uzivatele ON autor_id = uzivatele_id ORDER BY prezdivka;
Výsledek:
| TITULEK | PREZDIVKA |
|---|---|
| Bakterie | David |
| Pacman | David |
| Cheese Mouse | Denny |
| Algoritmus | Míša |
| Článek bez autora | (null) |
Vidíme, že článek se stejně vybral, i když se nepodařilo vybrat pravou část (tedy tu připojovanou, uživatele). Před spojováním tabulek je dobré se zamyslet, zda nastane případ, kdy se spojení nepodaří a co v tom případě chceme dělat. U článku by se toto v reálu stát asi nemělo.
RIGHT OUTER JOIN
Podobně jako levý vnější JOIN uznal vazbu v případě, že
levá část existovala, pravý JOIN to udělá naopak. Pokud bude
existovat uživatel (pravá, připojovaná část) a nebude k němu existovat
článek (levá část), bude stejně v tabulce zahrnut. Osobně jsem tento
JOIN ještě nepoužil. V tabulce jednoho takového uživatele
máme, je jím uživatel Emma. Oracle ještě navíc pro RIGHT JOIN
vyžaduje použití klíčového slovíčka OUTER, které bychom
mohli uvést i za LEFT JOIN, tam to ale není vyžadováno. Zkusme
si tedy RIGHT OUTER JOIN:
SELECT titulek, prezdivka FROM clanky RIGHT OUTER JOIN uzivatele ON autor_id = uzivatele_id ORDER BY prezdivka;
Výsledek:
| TITULEK | PREZDIVKA |
|---|---|
| Pacman | David |
| Bakterie | David |
| Cheese Mouse | Denny |
| (null) | Emma |
| Algoritmus | Míša |
Podle očekávání zmizel Článek bez autora a objevila se Ema.
Ještě nějaké JOINy bychom určitě v Oracle nalezli, ale pro naše účely nám toto bohatě stačí.
Wherování
Teoreticky se můžeme JOINům vyhýbat a používat místo nich jednoduše
jen klauzuli FROM a WHERE. Ve FROM
uvedeme více tabulek oddělených čárkami. Ve WHERE
specifikujeme podmínku spojení tabulek. Databáze si v ideálním případě
takovýto dotaz nejprve převede na INNER JOIN a poté ho
zpracuje:
SELECT titulek, prezdivka FROM clanky, uzivatele WHERE autor_id = uzivatele_id ORDER BY prezdivka;
Výsledek je tedy stejný jako při INNER JOINu:
| TITULEK | PREZDIVKA |
|---|---|
| Bakterie | David |
| Pacman | David |
| Cheese Mouse | Denny |
| Algoritmus | Míša |
Nevýhoda wherování je, že tak neuděláme všechny JOINy a v určitých případech mohou být dotazy méně optimalizované. Nikdy nevíme, jak dotaz databáze optimalizuje a optimalizace se bude lišit podle typu databáze. Tento způsob berte spíše jako zajímavost a nepoužívejte ho.
V následujícím cvičení, Řešené úlohy k 8.-9. lekci Oracle, si procvičíme nabyté zkušenosti z předchozích lekcí.
Měl jsi s čímkoli problém? Stáhni si vzorovou aplikaci níže a porovnej ji se svým projektem, chybu tak snadno najdeš.
Stáhnout
Stažením následujícího souboru souhlasíš s licenčními podmínkami
Staženo 12x (2.79 kB)
Aplikace je včetně zdrojových kódů
