
Lekce 6 - Microsoft AZURE - Stream Analytics Query Language

V minulé lekci jsme se věnovali Stream analytics v Azure a úložištím, dnešní díl by se dal shrnout do jednoduchého výrazu:
SELECT "through Stream Query" INTO “Table Storage“ FROM "IoT Hub"
My se jej dnes pokusíme implementovat. Doposud se nám podařilo definovat vstupy a výstupy a nyní se podíváme na sekci QUERY. V ní provádíme výběr a práci s daty za pomocí Stream Analytics Query Language. Jedná se upravené T-SQL a jeho popis, přesněji dokumentace, je k dispozici na adrese https://msdn.microsoft.com/…n834998.aspx. Dají se v něm psát SELECT výrazy, které nám umožní vybírat data proudící v reálném čase podle potřeb podobně jako v klasickém SQL. Těm, kdo s SQL výrazy pracují dennodenně, bude zápis velmi blízký a nebudou s ním mít dle mého názoru větší problémy.
Síla tohoto Stream analytics řešení je hlavně v jeho schopnosti zpracovávat velké množství dat na vstupu a posílat je přefiltrovaná na požadovaný výstup v reálném čase.
Na rozdíl od klasického SQL jak jej znáte, kdy děláte výběry nad daty v databázi, nám zde data neustále tečou nová a nová. Stream analytics Query pro výběry používá takzvaná okna - Windows. Jedná se o časový interval, ve kterém se nám nad daty udělá požadovaný SELECT. Lze volit mezi Tumbling, Hopping a Sliding window. Je to moc pěkně popsáno v dokumentaci, takže to proletíme jen zběžně. Odkaz je https://docs.microsoft.com/…dow-function.
- Tumbling window je okno, které vám bude vzorkovat data v pravidelném intervalu, například 10 sekund. Hodnoty se vám tedy ve vzorcích nebudou opakovat.
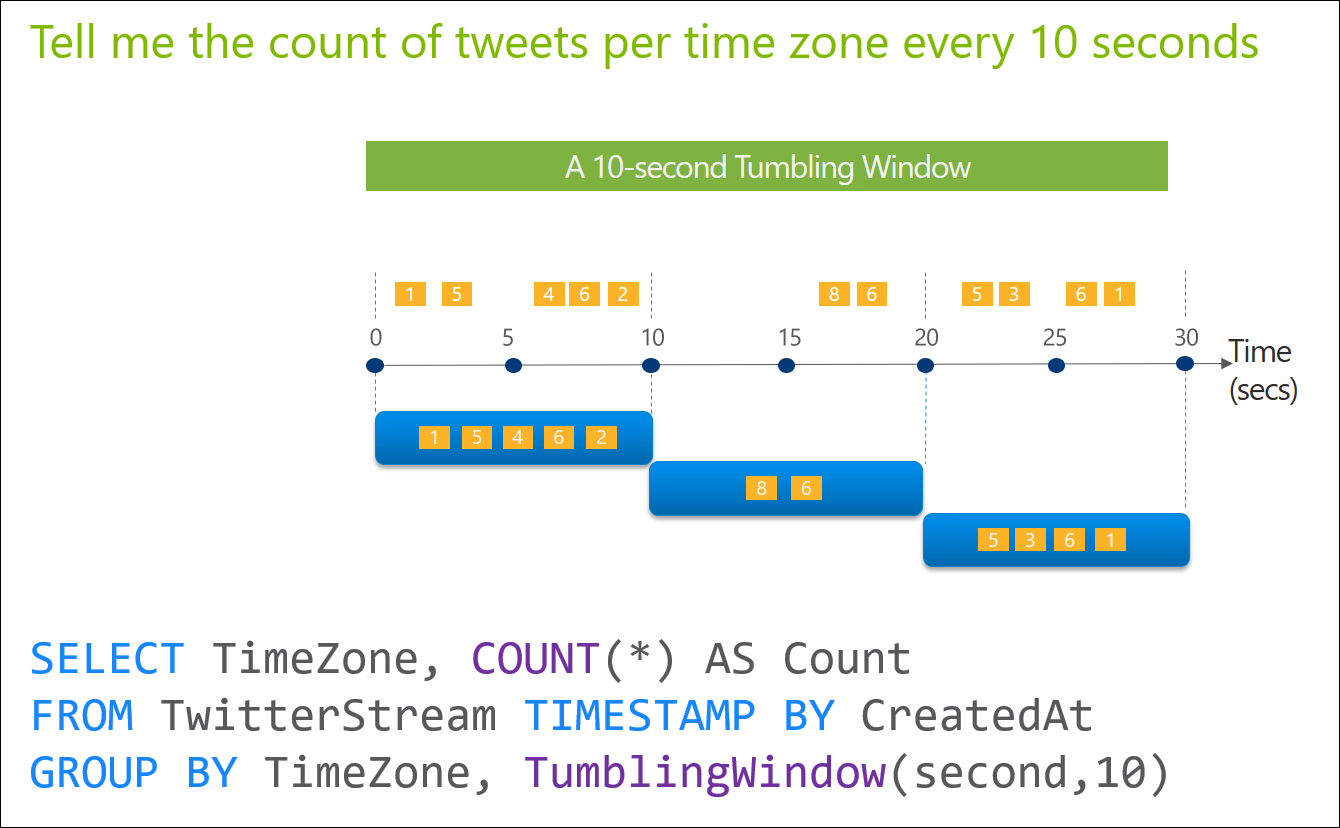
- Hopping window je okno, které vám bude vzorkovat v nějakém časovém intervalu, ale časová okna se vám budou o stanovený interval překrývat. Část hodnot se vám bude tedy ve vzorcích opakovat, ovšem o přesně stanovený časový interval.
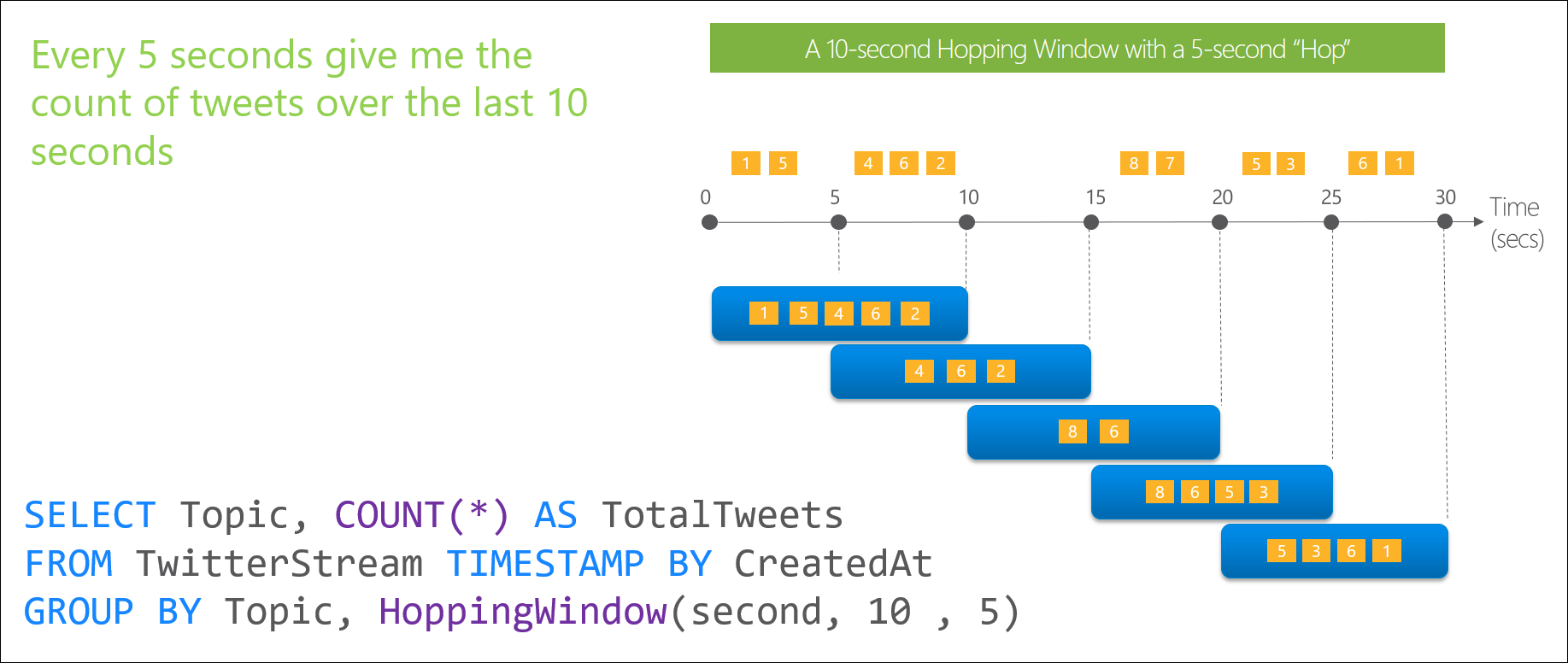
- Sliding window je okno, které jakoby klouže po datovém toku, a vždy, když se objeví data, pošle vám požadovaný interval předchozích dat. Chcete-li tedy vzorek dat o velikosti 10 sekund a každou vteřinu vám přijdou data, vybere se vždy 10ti sekundové okno, které se vám bude po vteřině měnit a po datech posouvat. 10 vteřinový vzorek vám ale přijde pouze při výskytu dat.
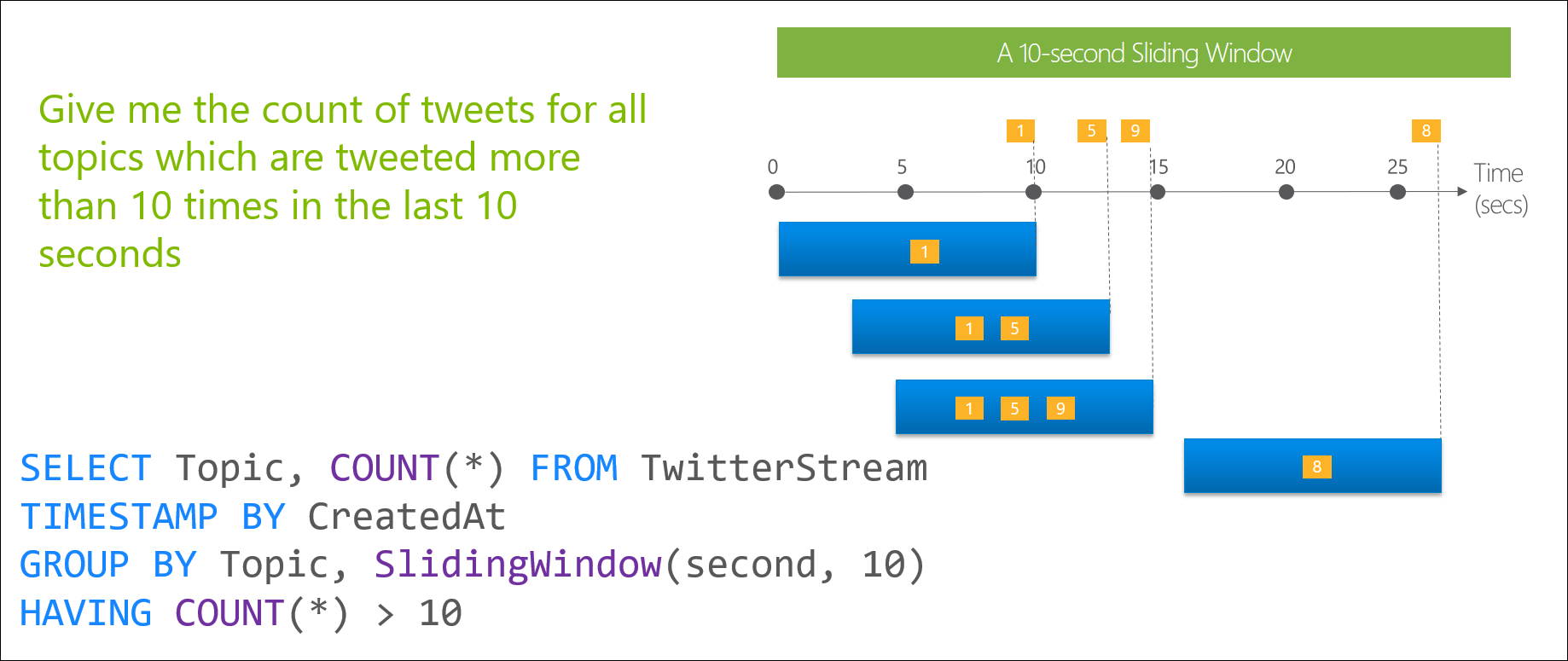
S takto vybranými daty poté můžete dělat co je libo anebo co nám jazyk dovolí. Například počítat maxima, minima, průměry a ukládat je do požadovaných výstupů. Ta celá legrace je jen o tom, že pracujete s daty v reálném čase a nikoli s daty například v databázi.
Necháme teorie a uděláme něco, z čeho bude užitek. 
Stream Analytics - Query ukládání dat do Table storage
Vstupme tedy do sekce QUERY. Objeví se nám editor Query výrazů.
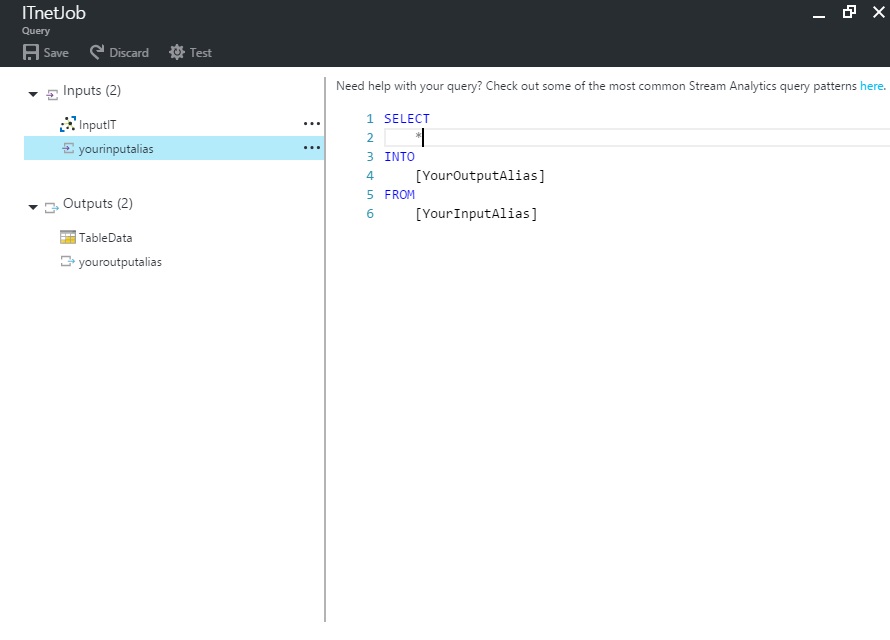
Navrhovaný kód vám bude hodně povědomý, a téměř supluje naše požadavky. Bohužel ale nebude fungovat dobře, proto jej budeme muset drobně upravit.
SELECT * INTO [YourOutputAlias] FROM [YourInputAlias]
Důvodem, proč jej musíme upravit, je, že v něm nejsou definovány hodnoty potřebné pro výstupní tabulku Table Storage.
Takže si je upravíme a doplníme naše vybrané hodnoty o potřebná data pro tabulku. Upravte tedy výraz následovně:
SELECT *, system.TimeStamp AS EventTime INTO [TableData] FROM [InputIT]
Ptáte se asi proč a co, že jsme to udělali?
Table Storage
Přidali jsme ke všem datům ze zprávy na vstupu reprezentovanými znakem * hodnotu časového razítka EventTime. System.TimeStamp je tedy interní metoda, která vrací čas příchodu paketu na rozhraní input StreamAnalytics, viz https://msdn.microsoft.com/…t598501.aspx
My ho budeme v naší výstupní tabulce používat jako unikátní
identifikátor řádku v tabulce, tzv. Row key, viz nastavení volby Row Key v
definici naší tabulky na výstupu. Ne nadarmo se tedy jmenují stejně
"EventTime"
Dále potřebujeme hodnotu DeviceId, který je obsažen v našich datech z desky jako identifikátor zařízení. Vzpomeňte si, zadávali jsme jej v Device Exploreru? DeviceId se tedy vybere hvězdičkou z našich dat na rozhraní input. Budeme jej používat pro naši tabulku jako volbu Partition Key. Jedná se o stringovou hodnotu, která slouží k jednoznačné identifikaci oddílu, kam se v Table storage budou ukládat naše data.
Je to řečeno dost nepřesně, protože se nestane nic složitějšího, než že do dat přidáme sloupec se jménem našeho zařízení, který již tam stejně je. Tady se ale použije pro identifikaci řádku. Asi se divíte, proč to děláme. Nu, inu, jelikož je to potřeba pro správnou funkci Table storage. Hodnoty Partition Key a Row Key je pár klíčů, které slouží jako unikátní identifikátor našich dat. Rozumějte, jedná se o jednoznačně identifikující klíče pro náš konkrétní záznam v tabulce. Tento pár klíčů je v table storage používán podobně je index v SQL databázi.
Table storage lze použít jako jednoduchou databázi pro naše projekty například v C#. K pochopení obou klíčů by měla pomoci definice objektové třídy, kterou lze používat ve vašich projektech.
public class IoTDataEntity : TableEntity { public IoTDataEntity(string partitionID , string timeStamp) { this.PartitionKey = partitionID; this.RowKey = timeStamp; } public IotDataEntity() { } public string Humidity { get; set; } public string Temperature { get; set; } }
Pro hlubší pochopení vás odkáži na samostudium v dokumentaci https://docs.microsoft.com/…o-use-tables.
Další část kódu, stream query, snad nepotřebuje hlubší vysvětlení. Řekněme si tedy snad závěrem, že všechna data ze vstupu vezmeme a doplníme je o jednoznačný identifikátor, časové razítko. Jméno našeho zařízení z našeho streamu (Device Id) a časové razítko TimeStamp (EventTime) plus výsledný soubor dat, tzv. "CONTENT", pošleme do výstupu. Tam se nám o ně s láskou sobě vlastní postarají malá skrčená stvoření žijící kdesi v AZURE a uloží je do Table storage.
Náš výraz tedy uložíme a spustíme si Stream Analytics tlačítkem Start na hlavní obrazovce. Po chvilce vyplněné pojídáním laskomin se služba spustí a my můžeme pozorovat oživnutí grafu Monitoring.
Data se nám začnou ukládat do naší tabulky. Bylo by skvělé se na ně podívat, ne? Na to se podíváme příště.
