
Lekce 11 - Pandas - Kombinování dataframů

V minulé lekci, Pandas - Matematické a statistické metody, jsme si ukázali některé matematické a statistické metody.
V tomto tutoriálu knihovny Pandas v Pythonu se zaměříme
na metody, které nám pomáhají efektivně kombinovat
dataframy. Ukážeme si metody jako concat(),
merge(), join() nebo update().
Kombinování dataframů v Pandas
Než si představíme dnešní téma, pojďme si nejprve importovat testovací data.
Import dat
Použijeme dataset s úbytkem zaměstnanců ve zdravotnickém sektoru v USA, který je dostupný v příloze na konci lekce.
Naimportujeme si data:
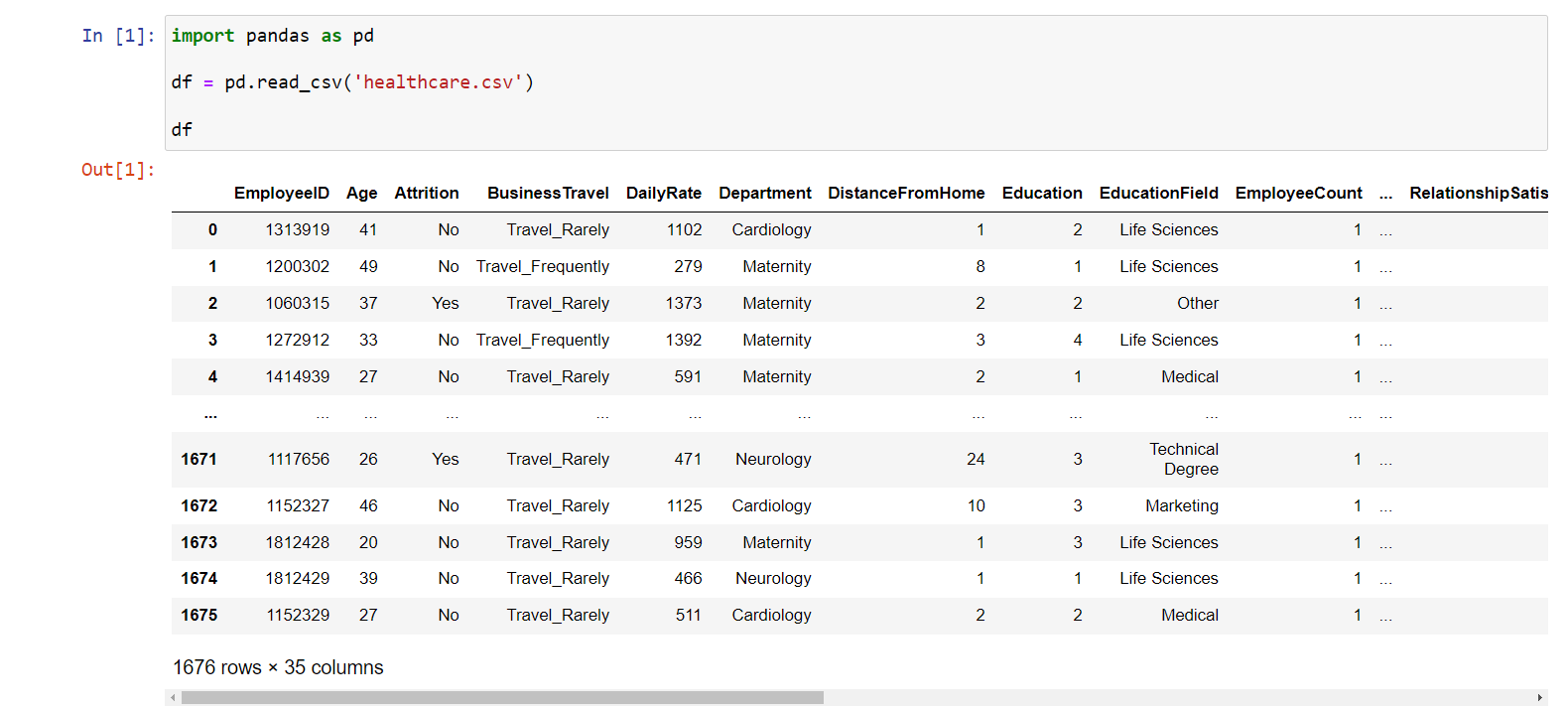
import pandas as pd df = pd.read_csv('healthcare.csv') df
Výsledek importu dat je následující:
Metody
Kombinování dat je klíčovou součástí analýzy, zvláště pokud pracujeme s různými zdroji dat nebo potřebujeme obohatit stávající dataset o další informace. Ukážeme si metody, které nám kombinování těchto dat umožňují.
concat()
Metoda concat() umožňuje spojit několik dataframů
podél řádků nebo sloupců. Spojování
probíhá bez ohledu na společné klíče nebo indexy.
Vybereme si zaměstnance ze dvou oddělení – Cardiology a
Neurology:
cardiology = df[df['Department'] == 'Cardiology'] neurology = df[df['Department'] == 'Neurology']
Tyto dva dataframy teď spojíme dohromady:
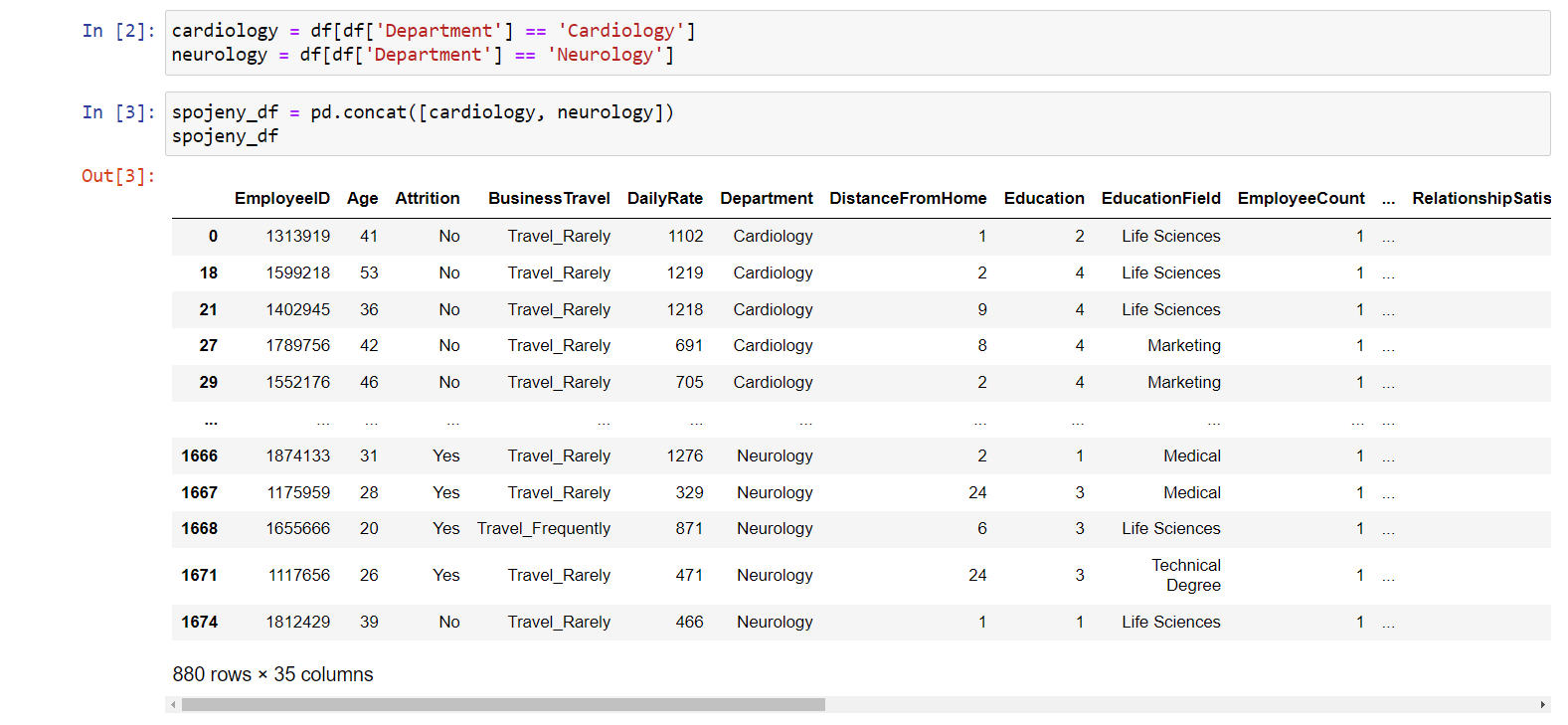
spojeny_df = pd.concat([cardiology, neurology]) spojeny_df
Vznikl nám dataframe se zaměstnanci z obou oddělení:
merge()
Pomocí metody merge() sloučíme dva dataframy na základě
společných sloupců nebo indexů. Možnosti
pro spojování dat určuje parametr how.
Parametr how
Parametr how přijímá několik hodnot:
left– Zachová všechny řádky z levého dataframu a odpovídající řádky z pravého dataframu. Pokud není nalezena shoda, vyplní řádek hodnotouNaN.right– Zachová všechny řádky z pravého dataframu a odpovídající řádky z levého dataframu. Pokud není nalezena shoda, vyplní řádek hodnotouNaN.inner– Zachová pouze řádky s odpovídajícími hodnotami v obou dataframech. Řádky bez shody jsou vyřazeny.outer– Zachová všechny řádky z obou dataframů. Řádky bez odpovídající hodnoty ve druhém dataframu jsou vyplněny hodnotouNaN.
Tvorba nového dataframu
Nyní si vyzkoušíme práci s merge(). Nejprve si vytvoříme
nový dataframe, který bude obsahovat pouze
EmployeeID a nový sloupec PreferredTransport:
doprava = {
'EmployeeID': [1414939, 1200302, 1060315, 1812428, 1313919],
'PreferredTransport': ['Car', 'Bike', 'Public Transport', 'Walk', 'Car']
}
df_doprava = pd.DataFrame(doprava)
Sloupec EmployeeID bude sloužit jako spojení mezi
dvěma dataframy. Vytvořili jsme pět záznamů s hodnotami
EmployeeID reálných zaměstnanců z našeho datasetu. Ve sloupci
PreferredTransport se bude nacházet preferovaný způsob dopravy
do práce.
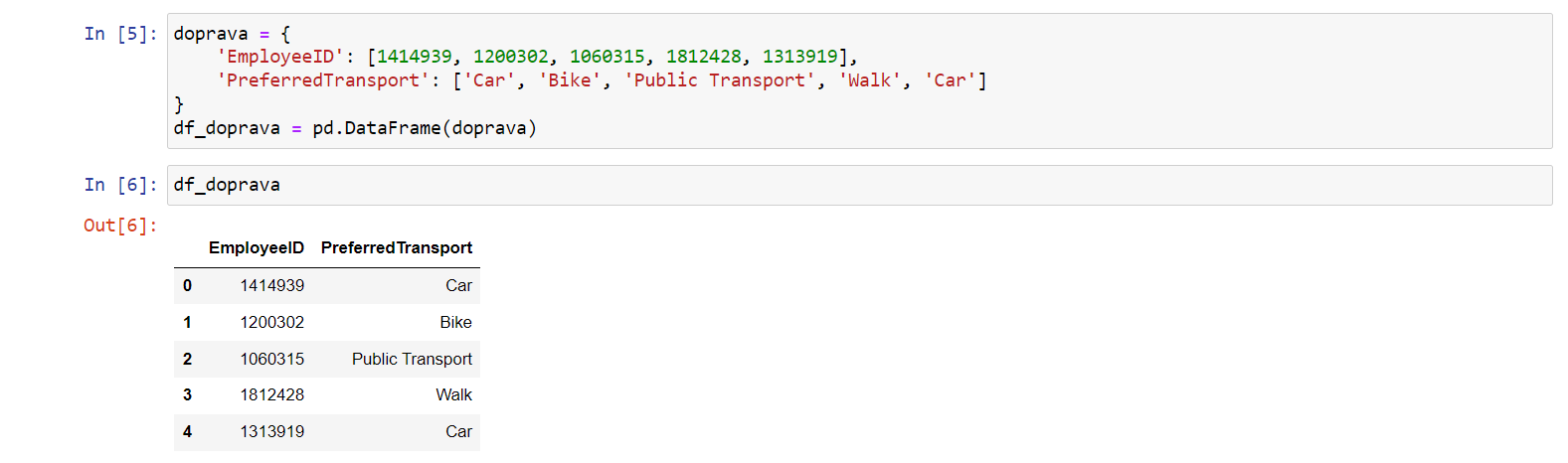
Nyní si tento nový dataframe zobrazíme:
df_doprava
Po spuštění kódu vidíme:
Hodnota left v parametru
how
Metodu merge() si nyní vyzkoušíme s vložením hodnoty
left do parametru how:
sloucene_df = pd.merge(df, df_doprava, on='EmployeeID', how='left') sloucene_df[['EmployeeID', 'PreferredTransport', 'Age']]
Výstupem bude opět nový dataframe, který ovšem obsahuje spojení dvou
dataframů – df a df_doprava. Při využití
merge() jsme postupně v parametrech on a
how předali oba dataframy.
Parametr on určuje sloupec, na kterém oba
dataframy propojujeme, a parametr how způsob, jakým
propojujeme.
Zobrazená data nyní vypadají takto:
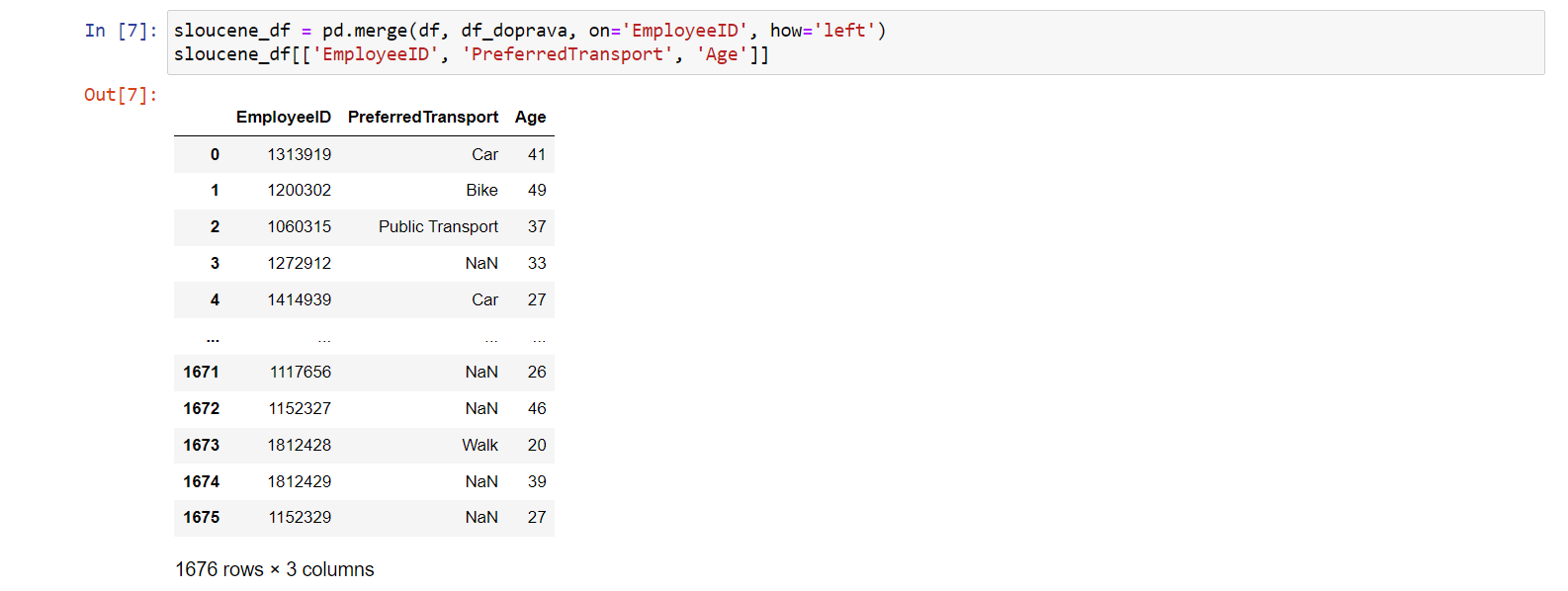
Všimněme si, že ne všechny hodnoty se vyplnily. Důvodem je, že jsme
použili způsob propojení left. Použila se tak data z dataframu
df a shoda se nenašla všude, proto má většina dat hodnotu
NaN.
Hodnota inner v parametru
how
Vyzkoušejme si nyní totéž, ale s využitím hodnoty inner.
Změňme si ještě název proměnné dataframu na
sloucene_df_inner (ten původní budeme ještě potřebovat):
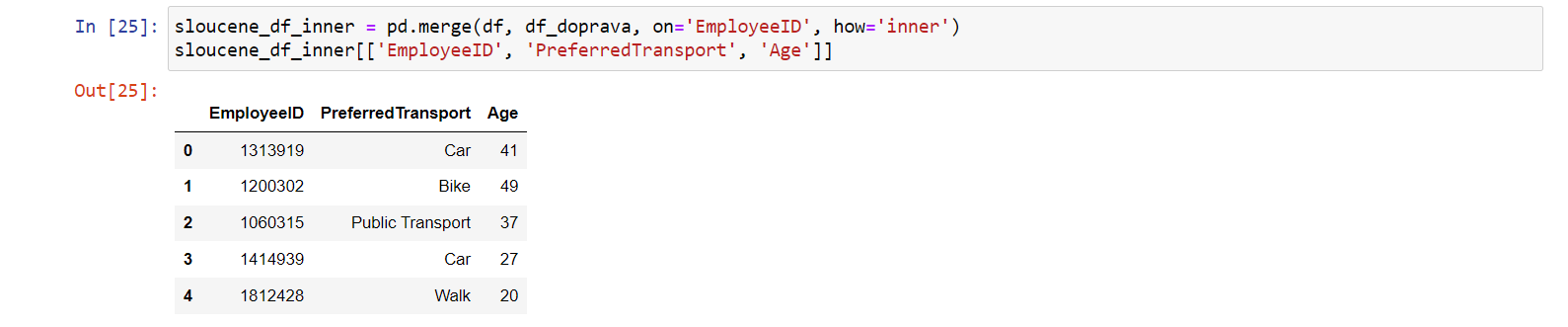
sloucene_df_inner = pd.merge(df, df_doprava, on='EmployeeID', how='inner') sloucene_df_inner[['EmployeeID', 'PreferredTransport', 'Age']]
Dostaneme teď pouze zaměstnance, u nichž se povedlo propojení:
join()
Metoda join() nám umožní spojit dva dataframy podle
indexů. Je obecně jednodušší na použití než
merge() a vhodná, chceme-li přidat další sloupce na základě
shodných indexů.
Připojme si informace o firemním členství zaměstnanců v klubu zdraví.
Klub zdraví bude charakterizován sloupcem HealthClubMembership,
který bude uložen v samostatném dataframu:
data_klubu_zdravi = {
'HealthClubMembership': ['Yes', 'No', 'Yes', 'No', 'Yes']
}
df_klub_zdravi = pd.DataFrame(data_klubu_zdravi).set_index(neurology.index[:5])
Dataframu df_klub_zdravi jsme nastavili správné
indexy využitím metody set_index(). Jako indexy jsme
vybrali prvních pět indexů z dataframu neurology.
Následně pomocí metody join() vytvoříme nový dataframe
propojený s dataframem neurology:
spojeny_df = neurology.join(df_klub_zdravi) spojeny_df[['EmployeeID','Age','HealthClubMembership','Department']].head(7)
Výstupem bude prvních sedm zaměstnanců z oddělení
neurology společně s informací, zda jsou v klubu zdraví, nebo
ne:
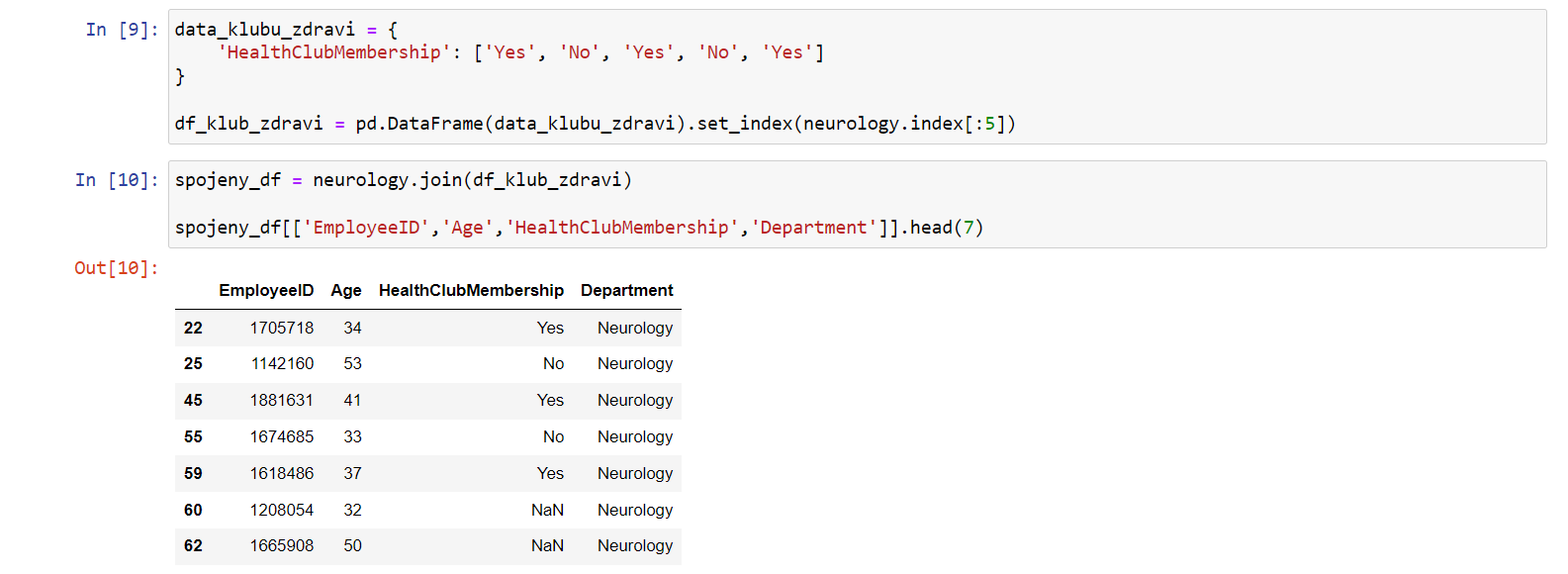
Nenalezený index se opět vyplní hodnotou
NaN.
combine_first()
Metoda combine_first() se používá k doplnění
chybějících hodnot v jednom dataframu hodnotami z jiného
dataframu. Při použití se zachová struktura prvního dataframu, ale
kombinují se dostupné informace z obou dataframů.
Metodu combine_first() si nyní vyzkoušíme k doplnění
několika hodnot, které jsme nevyplnili při použití merge() ve
sloupci PreferredTransport. Nejprve si tento dataframe
zobrazíme:
sloucene_df[['EmployeeID', 'PreferredTransport', 'Age']].head(10)
Dostaneme tento výstup:
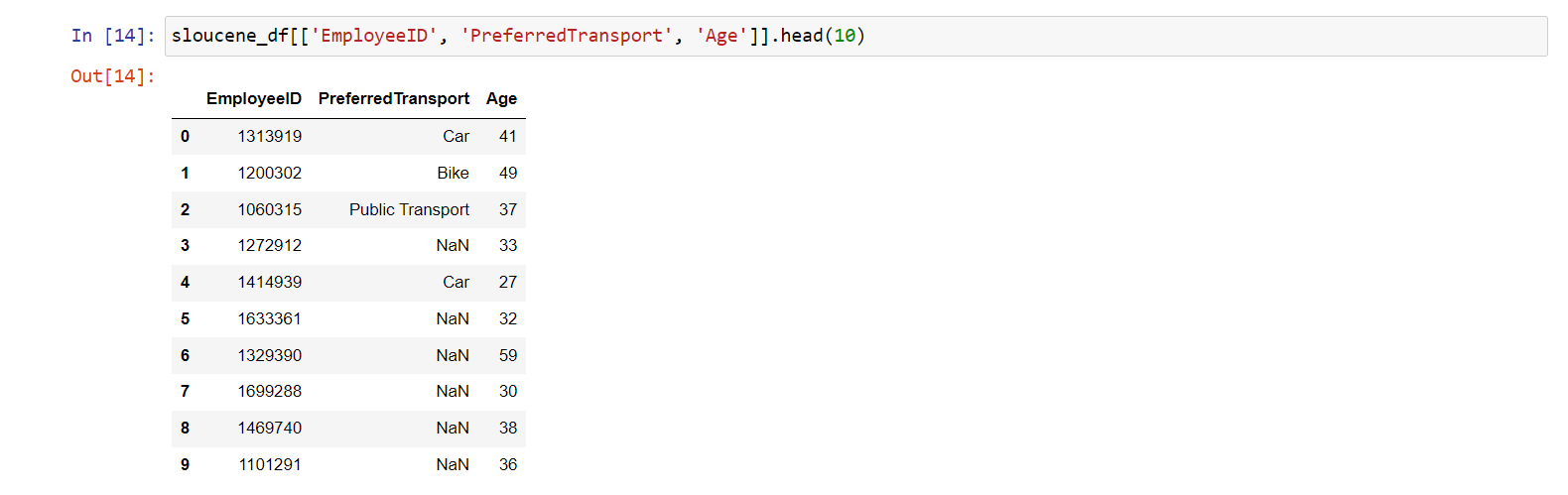
Zobrazili jsme si prvních deset řádků. Vidíme, že některé řádky
mají hodnotu NaN. Tento problém nyní vyřešíme.
Nejprve si připravíme data a z nich vytvoříme dataframe:
doprava = {
'PreferredTransport': [None, None, None, 'Public Transport', None, 'Car','Bus','Plane','Walk','Bike']
}
df_doprava = pd.DataFrame(doprava)
Následně dataframu sloucene_df nastavíme pro sloupec
PreferredTransport hodnoty z dataframu df_doprava
využitím metody combine_first a zobrazíme prvních deset
řádků:
sloucene_df['PreferredTransport'] = sloucene_df['PreferredTransport'].combine_first(df_doprava['PreferredTransport']) sloucene_df[['EmployeeID', 'PreferredTransport', 'Age']].head(10)
Ve výsledku tedy dostaneme náš původní dataframe
sloucene_df rozšířený o nové hodnoty, které byly doplněny
podle indexu:
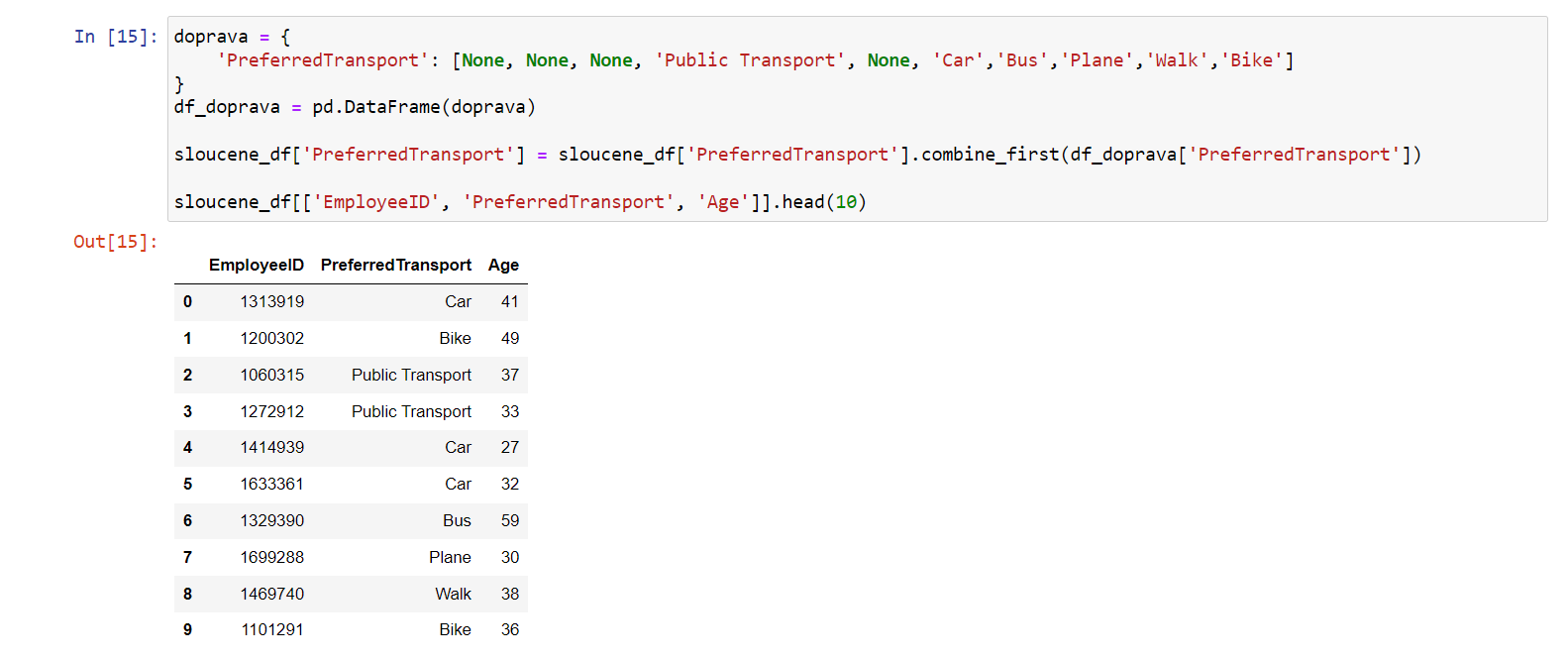
V našich datech doprava jsme nastavili některé
hodnoty PreferredTransport na None. Všimněme si, že
tato změna neproběhla, protože metoda combine_first() doplní
pouze prázdné hodnoty.
update()
Pomocí metody update() můžeme aktualizovat
hodnoty v jednom dataframu na základě jiného dataframu. Pojďme si
to vyzkoušet a aktualizujme měsíční platy a věk pro zaměstnance z
oddělení Cardiology. Nejprve se podívejme, jak vypadá prvních
pět zaměstnanců:
cardiology[['Age','MonthlyIncome']].head()
Výsledek:

Nyní upravíme zaměstnance na indexech 0 a 29.
Připravíme si data a vytvoříme z nich dataframe:
aktualizovana_data = {
'Age': [42,47],
'MonthlyIncome': [6050, 19000]
}
aktualizovany_df = pd.DataFrame(aktualizovana_data, index=[0, 29])
Museli jsme správně nastavit indexy, protože podle nich bude
update() probíhat.
Nakonec zavoláme metodu update() a opět zobrazíme data:
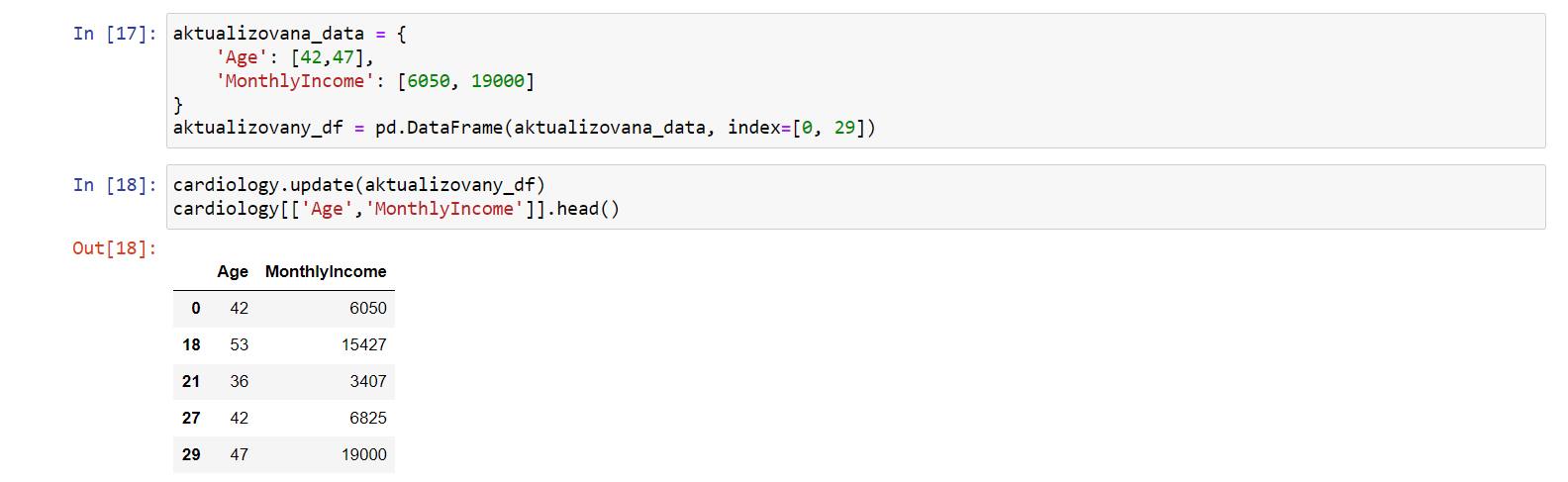
cardiology.update(aktualizovany_df) cardiology[['Age','MonthlyIncome']].head()
Výsledkem bude zestárnutí dvou zaměstnanců a zvýšení jejich platu:
V následující lekci, Pandas - Zpracování chybějících hodnot, si ukážeme užitečné metody pro zpracování chybějících hodnot v datech.
Měl jsi s čímkoli problém? Stáhni si vzorovou aplikaci níže a porovnej ji se svým projektem, chybu tak snadno najdeš.
Stáhnout
Stažením následujícího souboru souhlasíš s licenčními podmínkami
Staženo 36x (59.79 kB)
Aplikace je včetně zdrojových kódů v jazyce Python
