
Lekce 13 - Pandas - Metody pro výběr, řazení a analýzu dat Nové


V předchozím kvízu, Kvíz - Práce s řetězci, matematickými daty v Pandas, jsme si ověřili nabyté zkušenosti z předchozích lekcí.
V tomto tutoriálu knihovny Pandas v Pythonu se podíváme na metody pro výběr, řazení a analýzu dat.
Metody pro výběr, řazení a analýzu dat v Pandas
Ukážeme si, jak vybírat specifické části datasetu, řadit data podle různých kritérií a provádět analýzu pro získání důležitých informací a přehledů. Tyto techniky nám pomohou lépe porozumět datům a připravit je k dalším analýzám. Pojďme si však nejprve naimportovat data.
Import dat
Použijeme jiná data než v předchozích lekcích. Naimportujeme si
dataset, který simuluje úbytek zaměstnanců ve zdravotnickém sektoru v USA.
Dataset je vytvořen na základě reálných dat a snaží se předpovědět,
zda zaměstnanec zůstane ve firmě, nebo odejde. Jako vždy je csv
soubor dostupný v příloze na konci lekce.
Naimportujme si tedy dataset ze souboru healthcare.csv:
import pandas as pd df = pd.read_csv('healthcare.csv') df
Po provedeném importu vidíme data:
Výběr dat
Začneme zlehka. Nejdříve si ukážeme metody, kterými vybereme určitý počet řádků z našeho datasetu. Tyto metody uplatníme později, a to například v kombinaci s řazením. Využijeme tak vzor Method chaining, který je v Pandas velmi užitečný a běžně používaný.
Více se o vzoru Method chaining dozvíme v lekci Method chaining a method cascading.
head()
Pomocí metody head() zobrazíme prvních n
řádků z datasetu. Ve výchozím nastavení je to pět řádků, ale to
můžeme změnit. Zavolejme si head() na našem datasetu:
df.head()
Výstupem je skutečně prvních pět řádků:
tail()
Stejně jako jsme vybrali prvních n řádků pomocí
head(), můžeme také vybrat posledních n řádků
využitím metody tail().
Ať se neopakujeme, vybereme si posledních sto řádků:
df.tail(100)
Výstupem tedy bude posledních sto záznamů:
V zobrazení jich samozřejmě tolik neuvidíme, ale pracovat s nimi můžeme.
Řazení dat
Řazení dat je klíčová operace při práci s tabulkovými daty. Umožňuje nám uspořádat hodnoty v datasetu podle specifických kritérií, což je užitečné pro přehlednost, analýzu trendů nebo identifikaci extrémních hodnot.
V této části se zaměříme na několik základních metod, které nám pomohou data v Pandas seřadit. Tyto metody nám umožní řadit data buď podle hodnot ve sloupcích, nebo podle indexu či jiných specifických parametrů, jako jsou nejnižší nebo nejvyšší hodnoty ve sloupci.
Metody, které si ukážeme, zahrnují:
- řazení podle hodnoty ve sloupci metodou
sort_values(), - řazení podle indexu metodou
sort_index(), - přiřazování pořadí hodnotám ve sloupci metodou
rank().
sort_values()
Metoda sort_values() umožňuje řazení hodnot
v konkrétním sloupci dataframu. Hodnoty můžeme seřadit buď vzestupně,
nebo sestupně. Ve výchozím nastavení je seřazení vzestupně. Vzestupné
seřazení je udáváno parametrem ascending a hodnotou
True.
Pojďme si seřadit záznamy podle měsíčního příjmu, znázorněného
sloupcem MonthlyIncome. Vybereme si pouze tento sloupec a
následně zavoláme metodu sort_values():
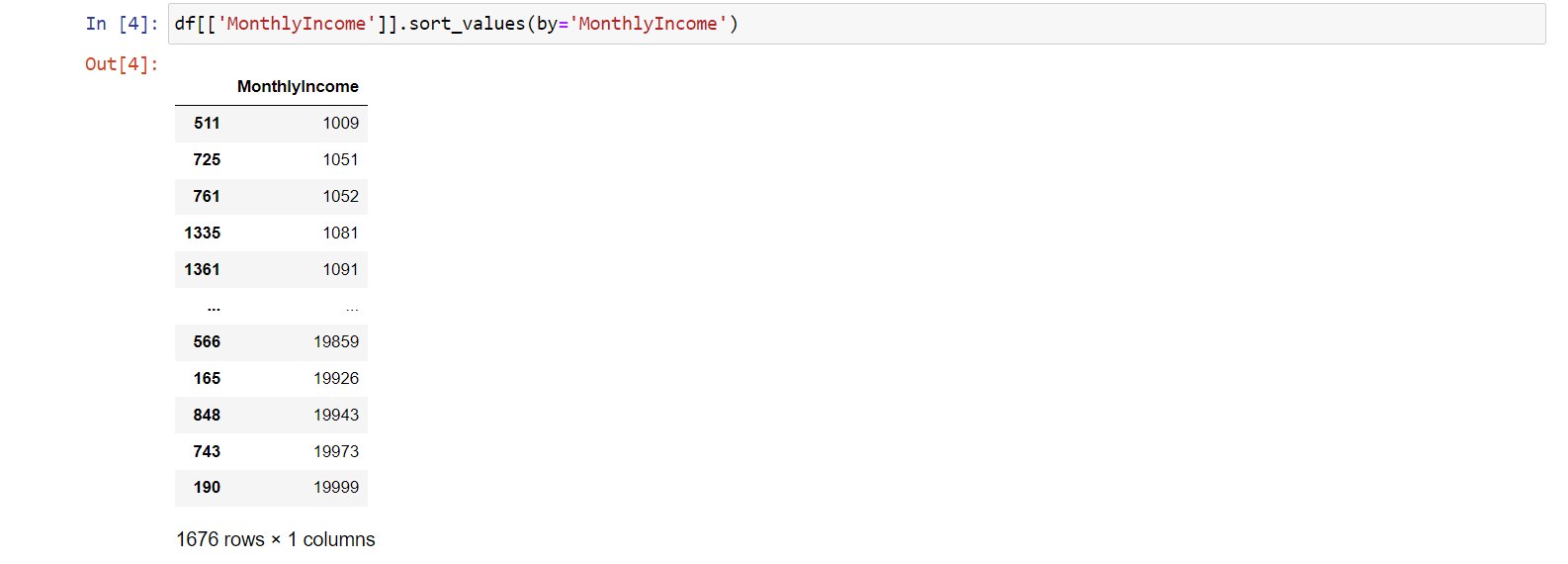
df[['MonthlyIncome']].sort_values(by='MonthlyIncome')
Dále jsme v metodě sort_values() přidali parametr
by, který určuje sloupec, podle něhož řadíme.
Z dat vidíme seřazení měsíčních platů v dolarech od nejmenšího po největší:
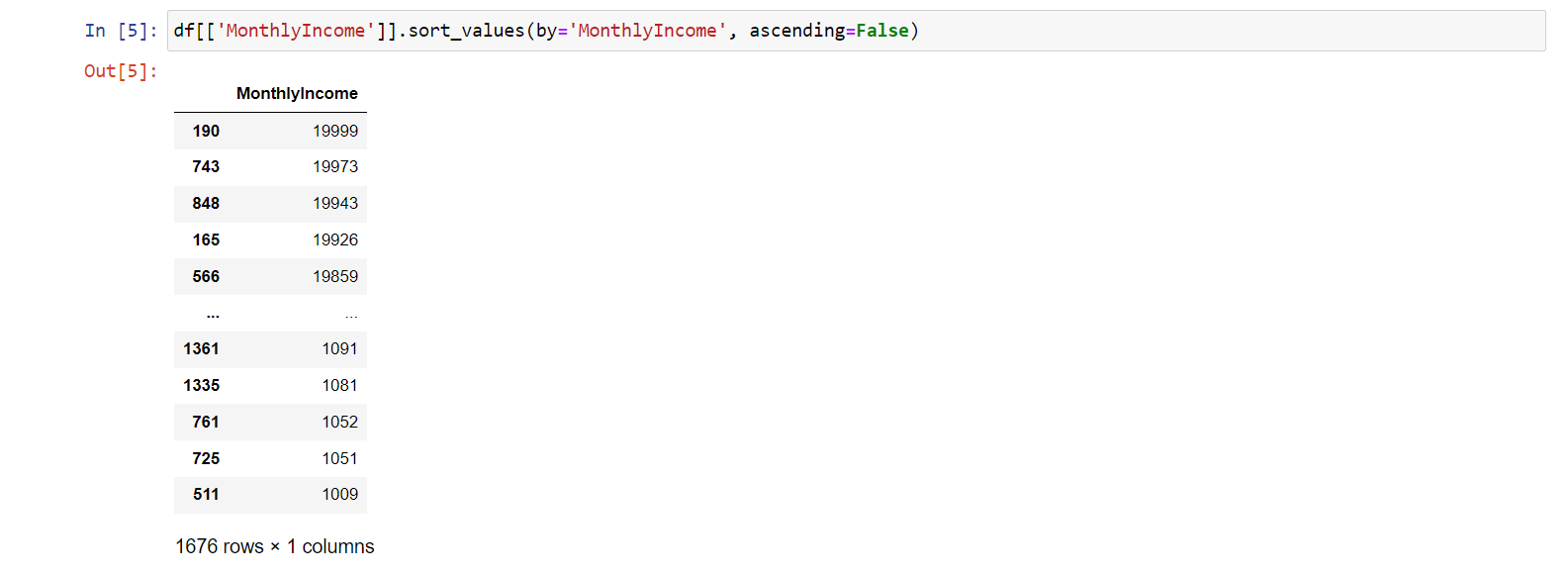
Zkusme to i obráceně. Přidáme parametr ascending a
nastavíme jeho hodnotu na False, čímž docílíme sestupného
řazení:
df[['MonthlyIncome']].sort_values(by='MonthlyIncome', ascending=False)
Nejvyšší plat tak nyní bude nahoře:
sort_index()
Metoda sort_index slouží k řazení řádků
podle jejich indexu. Pokud máme indexy v neuspořádaném
pořadí, můžeme je seřadit tak, aby byly uspořádány vzestupně nebo
sestupně. Data v našem datasetu mají záznamy seřazeny vzestupně, proto si
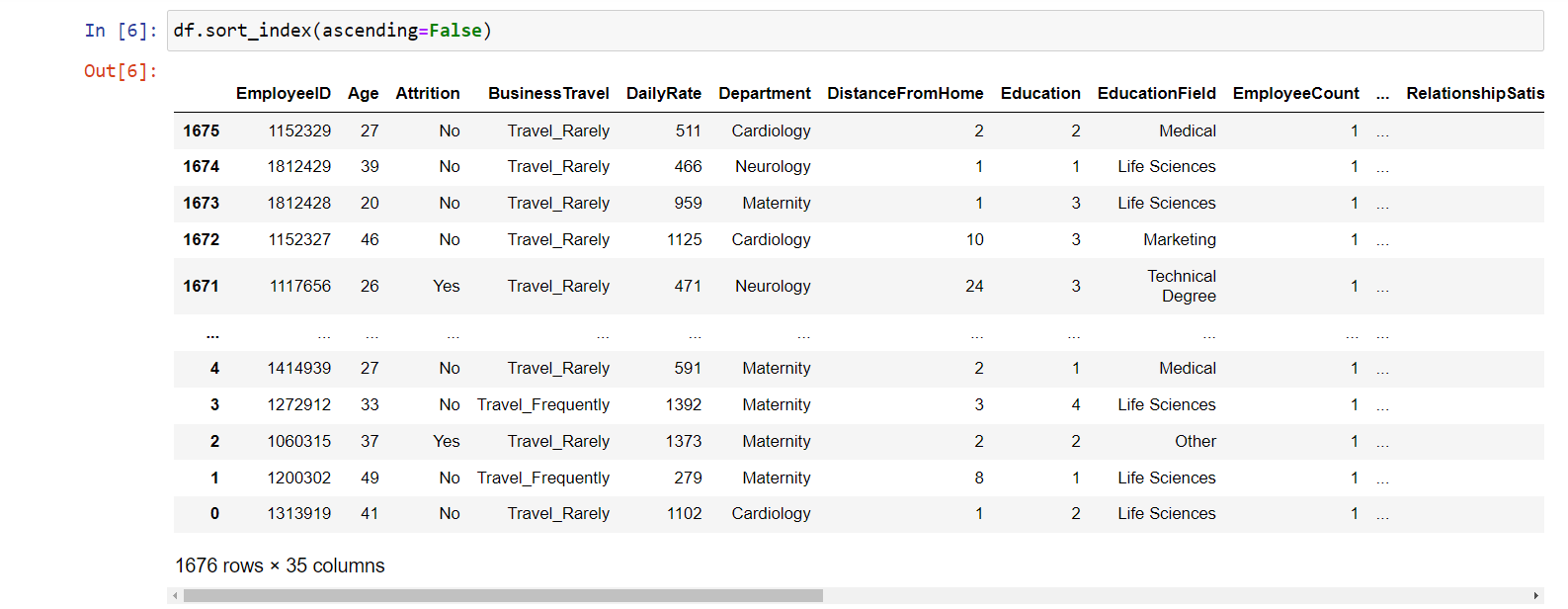
je zkusíme seřadit sestupně.
Podobně jako tomu bylo u metody sort_values(), využijeme
parametr ascending, do něhož vložíme hodnotu
False:
df.sort_index(ascending=False)
Výstupem bude sestupné řazení všech dat podle indexu:
rank()
Metoda rank() přiřadí pořadí hodnotám ve
sloupci podle jejich velikosti. Nejmenší hodnota obdrží
pořadí 1, druhá nejmenší 2 a největší pak v
případě našeho datasetu 1676. Při shodných hodnotách se
pořadí určuje podle parametru metody.
Metoda může přijímat v parametru method tyto hodnoty:
average– průměrné pořadí pro shodné hodnoty,min– nejnižší možné pořadí shodné hodnoty,max– nejvyšší možné pořadí pro shodné hodnoty,first– pořadí se určí podle pořadí v datasetu.
Pojďme si ukázat, jak rank() funguje. Nejdříve si vybereme
několik záznamů pomocí metody head() a přidáme uměle shodnou
hodnotu, abychom viděli rozdíly v různých režimech řazení:
df_rank = df[['MonthlyIncome']].head(10) df_rank.loc[0, 'MonthlyIncome'] = 3468 df_rank['MonthlyIncome'].rank(method='average')
Ve výstupu tedy dostaneme:
Dostali jsme deset hodnot, kde každá má své pořadí, které je hodnoceno
číslicemi 1.0 až 10.0. Dvě hodnoty se nám
opakují, a proto mají shodné pořadí 6.5. Docílili jsme toho
právě využitím hodnoty average v parametru
method.
Vyzkoušejme si totéž i při použití hodnoty max. Aby toho
nebylo málo, seřaďme si pořadí sestupně využitím nám již známé
metody sort_values():
df_rank['MonthlyIncome'].rank(method='max').sort_values(ascending=False)
Vidíme, že pořadí je nyní seřazeno od největšího po nejmenší a
opakující se hodnoty mají obě pořadí 7.0, protože jsme
využili hodnotu max:
Analýza dat
Analýza dat nám pomůže získat náhled do struktury datasetu, identifikovat nejvyšší a nejnižší hodnoty, rozložení dat nebo odhalit případné anomálie. Ukážeme si některé metody, které slouží k těmto účelům.
nsmallest()
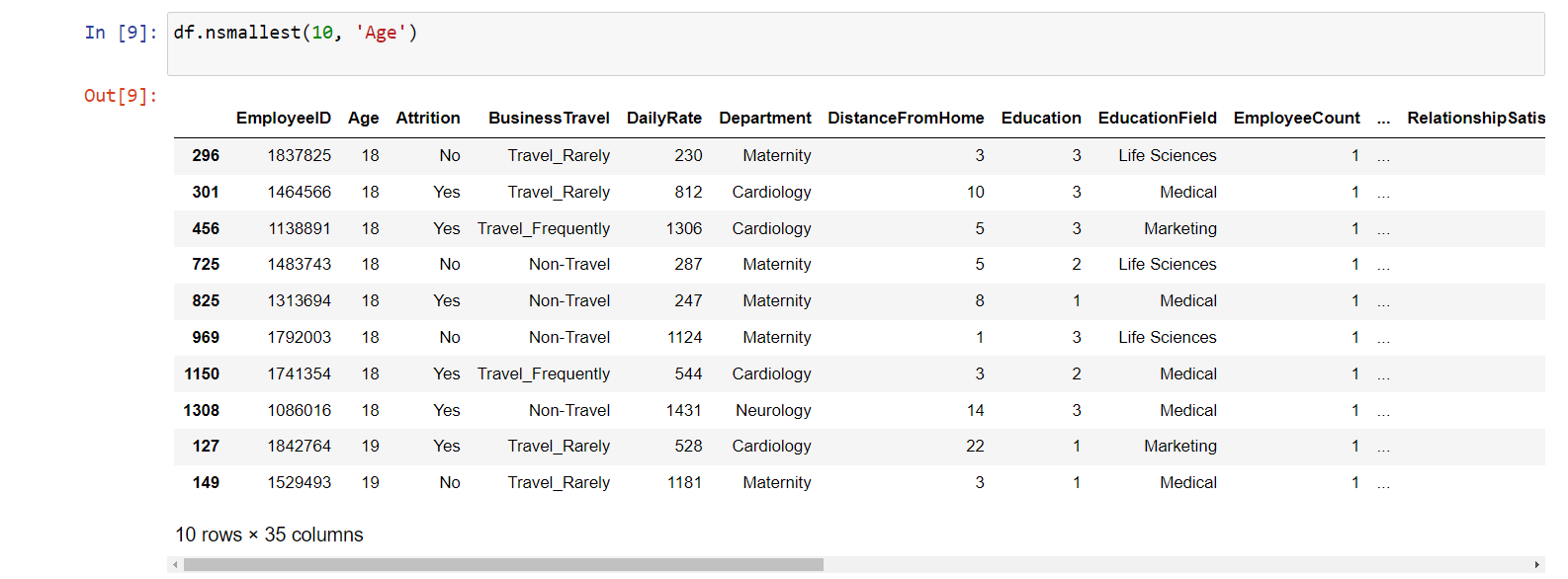
Metoda nsmallest() slouží k výběru n řádků s
nejnižšími hodnotami v určitém sloupci. Můžeme ji
využít například k identifikaci deseti nejmladších zaměstnanců:
df.nsmallest(10, 'Age')
Výstupem je deset nejmladších zaměstnanců:
nlargest()
Pojďme na to obráceně. Vybereme si n největších
hodnot. Právě k tomu slouží metoda nlargest().
Tentokrát přidáme něco navíc. Kromě věku si přidáme ještě sloupec
DistanceFromHome a získáme si tak deset nejstarších
zaměstnanců s největší vzdáleností od domova:
df.nlargest(10, ['Age', 'DistanceFromHome'])[['Age', 'DistanceFromHome']]
Ve výstupu vidíme:
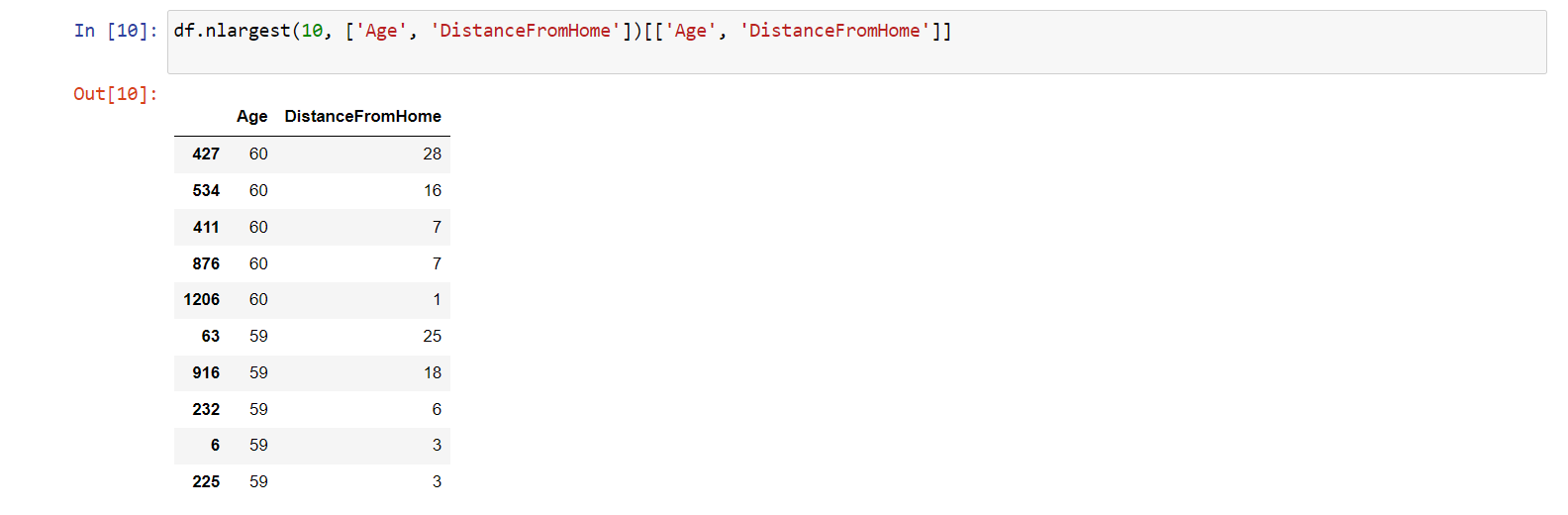
Všimněme si, že ačkoli to někteří zaměstnanci mají od domova dál,
jsou zobrazeni níže, protože jsou mladší. Hlavním určujícím faktorem je
tedy sloupec Age a až poté sloupec
DistanceFromHome.
sample()
Jako poslední si představíme metodu sample(). Využitím
sample() můžeme náhodně vybrat řádky z
datasetu. Zvolit si můžeme počet řádků nebo procentuální podíl dat.
Vybereme si tedy patnáct náhodných řádků:
df.sample(15)
Ve výstupu vidíme:
Vyzkoušejme si metodu znovu, ať se ujistíme, že data jsou opravdu
náhodná. Pro náhodný výběr učitého procenta záznamů
využijeme parametr frac a nastavíme hodnotu. Nastavme si, že
chceme 30 % záznamů:
df.sample(frac=0.3)
Ve výstupu dostaneme něco přes pět set záznamů:
V následující lekci, Pandas - Práce s multiindexy, se zaměříme na práci s multiindexy, které poskytují mocné nástroje k organizaci a analýze složitějších dat.
Měl jsi s čímkoli problém? Stáhni si vzorovou aplikaci níže a porovnej ji se svým projektem, chybu tak snadno najdeš.
Stáhnout
Stažením následujícího souboru souhlasíš s licenčními podmínkami
Staženo 7x (59.79 kB)
Aplikace je včetně zdrojových kódů v jazyce Python
