
Lekce 3 - Předpověď ceny zlata pomocí lineární regrese v Pythonu


V minulé lekci, Neuronové sítě v Pythonu - Prostředí Jupyter, jsme si představili prostředí Jupyter notebook pro Python.
Vítejte u další lekce, dnes si zkusíme předpovídat data pomocí
lineární regrese a pracovat s .csv soubory pomocí knihovny
Pandas. Jak víte, než se dostaneme k neuronkám nám ještě chvíli potrvá

Lineární regrese
Určitě se mnozí z vás setkali s tímto vzorečkem:
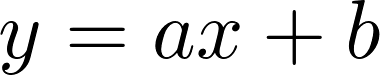
Je to předpis lineární funkce. Tyto funkce jsou nám lidem velmi blízké a také jednoduché na pochopení.
Jablka
Představme si např. úlohu na sběr jablek v sadu. 1 farmář
sebere 200 jablek za hodinu. x farmářů sebere
y = ax jablek za hodinu, v našem případě se
a = 200. Máme zde jednoduchý lineární vztah mezi x
a y.
- Koeficient
aje sklon funkce, čím více jeden formář dokáže jablek sebrat, tím více nám s každým farmářemypovyroste. bje tzv. bias (tento výraz rozebereme později u neuronových sítích) a dovoluje funkci posun, aby se lépe přizpůsobila datům. Můžeme např. říci, že ve skladu je již v základub = 500jablek a výsledek funkce bude vždy o500jablek vyšší, bez ohledu na hodnotyxay.
Zlato
Přejděme na zajímavější komoditu. Řekněme, že programujeme jednoduchý předpovídač ceny zlata a historická data již máme.

Pro předpověď potřebujeme vytvořit přímku tak, aby prošla co nejvíce body v datasetu (jednoduše soubor dat, který chceme předpovídat) a tedy odpovídala co nejpřesněji tomu, jak cena zlata roste nebo klesá. Právě pomocí lineární regrese zjednodušíme velké množství bodů (cen zlata v daný okamžik) na pouhou přímku, čímž samozřejmě ztratíme určitou přesnost. Této metodě "osekání" nějaké složité funkce na podobnou jednodušší funkci se v matematice obecně říká aproximace.
Abychom lineární funkci přizpůsobili, potřebujeme ji takzvaně
"optimalizovat". To se týká proměnných a a b,
jelikož x je vstup (v tomto případě čas). Ukážeme si 2
způsoby, jak můžeme funkci optimalizovat:
- Dopočítání z dat - Spočítáme sklon
aa následněb - Gradientní metoda - U této metody vybereme
aabnáhodně a postupně je podle námi definované chybové funkce optimalizujeme, dokud není chyba co nejmenší
Výpočet ceny zlata v Pythonu
Nyní již známe vzorec pro lineární funkci a můžeme si tedy ukázat jednoduchý příklad v Pythonu. Spusťme si prostředí, které jsme si představili v minulé lekci, a dle potřeby si vytvořme nový notebook.
Import knihoven
Nejdříve je potřeba importovat knihovny s kterými budeme pracovat:
from sklearn.linear_model import LinearRegression import numpy as np import matplotlib.pyplot as plt
Zjednodušený příklad
Než se vrhneme na reálné ceny zlata, začneme jednodušším příkladem.
Vstupní a výstupní data
Pro ukázku si definujeme jednoduchý příklad: Chceme výstup o
2 větší než vstup. V tomto případě chceme sklon
a = 1 a bias b = 2.
Funkci můžeme rychle ověřit při vstupu 3:
y = 1 * 3 + 2y = 5
V kódu pro tyto hodnoty definujeme vstupní a výstupní data, čímž nasimulujeme podobný případ jako se zlatem - máme hodnoty před a po změně, ale nevíme vzoreček, jakým změny předpovídat. Budeme se tedy snažit uhádnout naši lineární funkci:
# Definujeme si vstupní data, v tomto případě 1 a 3 x = np.array([[1], [3]]) # Definujeme si výstup, který chceme. # Pokud je vstup 1, chceme výstup 3 # Pokud je vstup 3, chceme výstup 5 y = np.array([[3], [5]])
Regressor
Data jsou připravena, nyní si můžeme vytvořit Regressor
neboli lineární funkci a optimalizovat ji na naše data:
# Vytvoříme regressor neboli lineární funkci reg = LinearRegression() # Optimalizujeme reg.fit(x, y)
Metodě fit() jednoduše předáme vstupní a výstupní data a
ona zjistí vztah mezi nimi. Jak si funkce vede ověříme pomocí metody
score().
reg.score(x, y)
Výsledek:
1
Metoda vrátila výsledek 1, což znamená, že mezi
x a y je vysoká korelace neboli vztah. Když
x stoupá, y také stoupá, přesněji o
2. Zjednodušeně to znamená, že naše funkce protíná všechny
body, jak i uvidíte dále v grafu.
Vytvoříme si tedy graf pro vizualizaci funkce, kterou zjišťujeme, a bodů, které již máme z dat:
# Pomocí funkce plot() se vykreslí čárový graf plt.plot(x, reg.predict(x)) # Pomocí funkce scatter() vykreslíme jednotlivé body v grafu # V tomto případě body [1, 3] a [3, 5] plt.scatter(x, y, c="r") # v parametru c specifikujeme styl bodů, chceme je červené
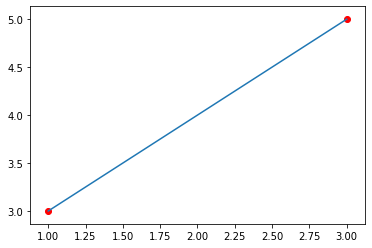
Vidíme, že metoda predict() nám zobrazila přímku
odpovídající změně našich dat. Metoda scatter() na ni pak
dále vykreslila body, v našem případě jen dva.
Zobrazíme si sklon a bias funkce a ověříme si tak, že jsme měli pravdu:
a = reg.coef_ b = reg.intercept_ print("Sklon je {} a bias je {}".format(a, b))
Výsledkem jsou opravdu koeficienty lineární funkce, podle které jsme data vytvořili:
Sklon je [[1.]] a bias je [2.]
Zlato!
Už umíme předpovídat data za pomoci knihovny scikit-learn,
proto se vrhneme na příklad s reálnými daty o ceně zlata.
Příprava reálných dat
Ještě předtím než začneme, potřebujeme data. Ta můžeme stáhnout
např. zde : https://pkgstore.datahub.io/…thly_csv.csv.
Stažený .csv soubor přesuneme do složky s aktuálním
.ipynb notebookem. Pokud nevíte, kde se nachází, přesuňte se
na předchozí záložku v prohlížeči a tam bude běžící notebook označen
zeleně:
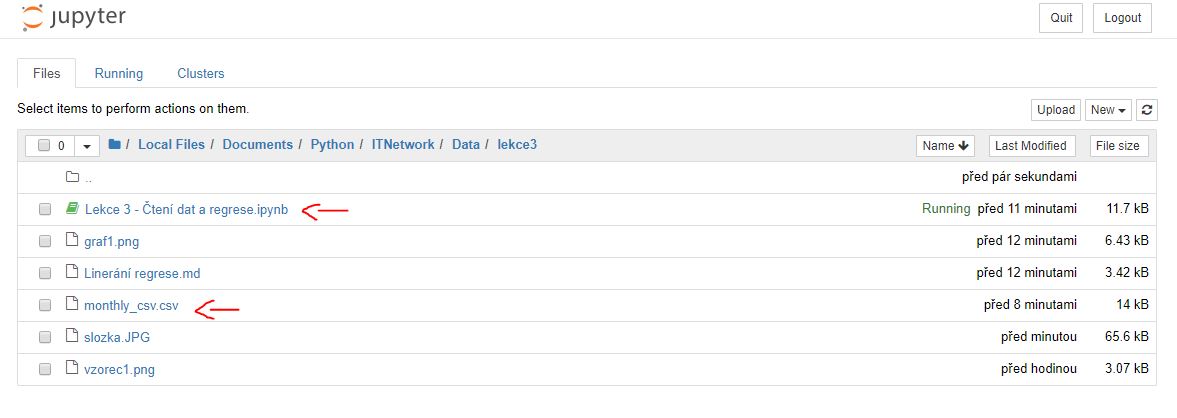
Výtečně, soubor monthly_csv.csv máme v naší pracovní
složce a můžeme se tedy vrhnout na tvorbu předpovídače.
Importy
Importujeme si tedy ještě knihovnu Pandas pro čtení dat z
.csv, naše prvotní importy ponecháme:
import pandas as pd
Čtení dat
Přečteme data ze souboru a zobrazíme si hlavičku neboli prvních 5
řádků .csv souboru:
data = pd.read_csv("monthly_csv.csv")
data.head()
Výsledek:
Date Price 0 1950-01 34.73 1 1950-02 34.73 2 1950-03 34.73 3 1950-04 34.73 4 1950-05 34.73
Jak můžeme vidět, dataset obsahuje 2 vlastnosti: Datum a
Cenu. Datum budeme reprezentovat jako počet měsíců
od 1.1.1950, což je začátek datasetu. V den, kdy jsem tento článek psal, je
maximální index 833, což je 1.6.2019.
Vstupy a výstupy
Připravíme si tedy opět vstupy a výstupy:
# numpy pole od 0 do 833 ve dne 14.6.2019 x = np.arange(len(data)) # Ceny převedeme na numpy pole y = data["Price"].to_numpy()
Data ještě musíme převést do tvaru, který funkce fit()
požaduje, což je (vzorek, vlastnosti). My zatím máme jen
(hodnoty).
Představte si vzorek jako člověka a hodnoty jako nějaké jeho vlastnosti,
jako např. výška a váha. Vstup by v tomto
případě vypadal takto: [ [173, 71] ]. Pokud bychom chtěli více
lidí, vypadal by vstup takto: [ [173, 71], [183, 86] ].
My tedy potřebujeme převést Cena a Datum na
tento tvar, jelikož zatím mají tvar:
[34.73, 34.73, 34.73, 34.73, 34.73] a
[0, 1, 2, 3 4, 5]. Náš požadovaný tvar vypadá takto:
[ [34.73], [34.73], [34.73], [34.73], [34.73] ] a
[ [0], [1], [2], [3], [4], [5] ].
Jelikož je knihovna NumPy dělaná na práci s
n-dimenzionálními poli, toto je jednodušší, než se zdá. Stačí použít
funkci reshape() a zadat žádaný tvar. Funkci můžeme zadat tvar
například (32, 2), pokud velikost pole sedí, tedy je
64 => 32 * 2 . Pokud funkci zadáme (-1, 2),
automaticky si dopočítá chybějící dimenzi, takto lze použít pouze na
jednu dimenzi.
Nejdříve si zobrazíme tvar x před změnou tvaru:
x.shape
Výsledek:
(834,)
Změníme tvar x a y:
x = x.reshape(-1, 1) y = y.reshape(-1, 1)
A tvary si vypíšeme:
x.shape, y.shape
Výsledek:
((834, 1), (834, 1))
Lineární regrese
Nyní pojďme zobecnit pohyb ceny zlata na jednoduchou lineární funkci.
Data jsou připravená, vytvoříme si tedy LinearRegression() a
optimalizujeme funkci pomocí metody fit():
reg = LinearRegression() reg.fit(x, y)
Podíváme se, jak si funkce vede pomocí metody score().
reg.score(x, y)
Výsledek:
0.6859359867746044
Jak jsme asi tušili, tak jednoduché to nebude Funkce si nevede nějak dobře, to
nám značí, že Cena není tak moc závislá na
Datum. Vizualizujeme si vše v grafu, abychom se
přesvědčili:
plt.plot(x, reg.predict(x))
plt.scatter(x, y, c="r")
Výsledek:
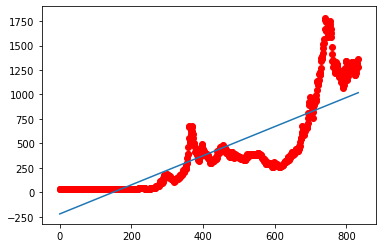
I přesto, že funkce není ideální, bude zajímavé zjistit, jakou
předpoví Cenu pro datum 1.7.2025 oproti dnešku. To je dle mých
výpočtů index 906. Cena dnes je:
data["Price"][833]
Výsledek:
1358.4879999999998
A cena v roce 2025:
reg.predict([[906]]).item()
Výsledek:
1126.481982068847
Náš jednoduchý předpovídač předpovídá, že zlato rozhodně není vhodná investice. O tom zda je to pravda, se ještě dozvíme u polynomiální regrese, která si s tím dokáže poradit lépe. To vše se brzy dozvíte v následujících lekcích.
V následujícím kvízu, Kvíz - Základy neuronových sítí v Pythonu, si vyzkoušíme nabyté zkušenosti z předchozích lekcí.
Měl jsi s čímkoli problém? Stáhni si vzorovou aplikaci níže a porovnej ji se svým projektem, chybu tak snadno najdeš.
Stáhnout
Stažením následujícího souboru souhlasíš s licenčními podmínkami
Staženo 156x (59.61 kB)
Aplikace je včetně zdrojových kódů v jazyce Python
